저자: Nan Jiang, Zimo He, Wanhe Yu, Lexi Pang, Yunhao Li, Hongjie Li, Jieming Cui, Yuhan Li, Yizhou Wang, Yixin Zhu, Siyuan Huang | 날짜: 2025-12-30 | DOI: 10.48550/arXiv.2512.24321 📄 PDF
Essence

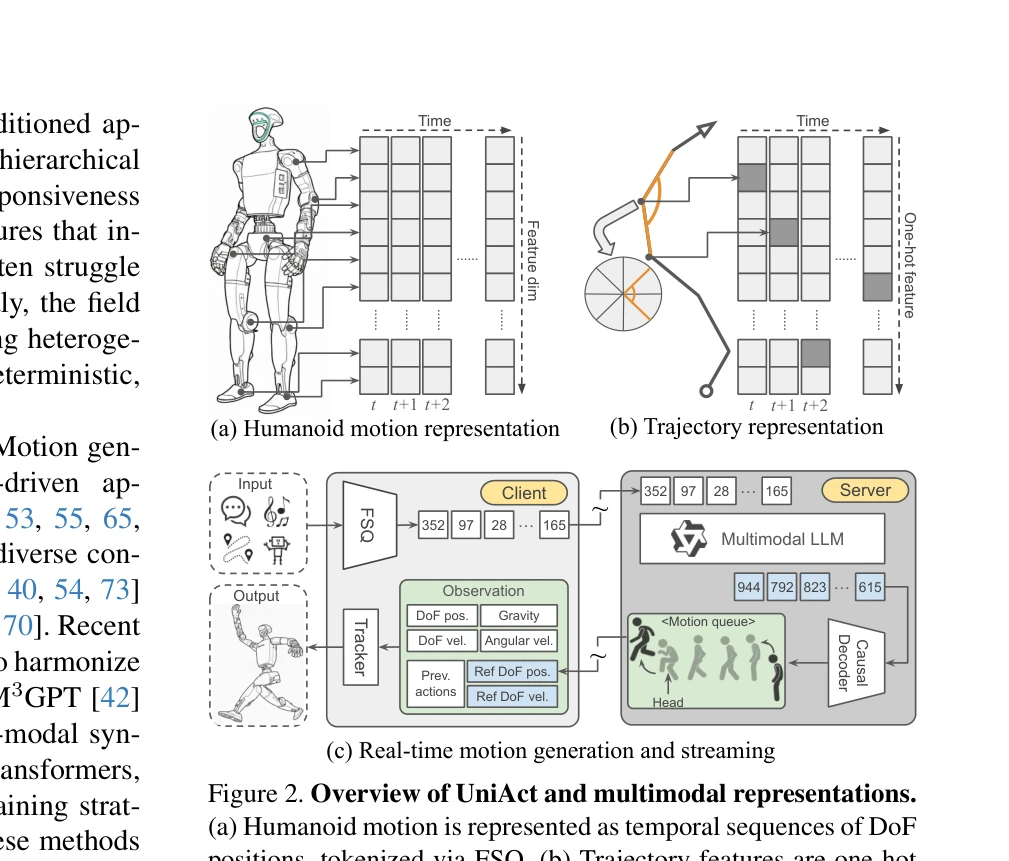
Figure 1. UniAct, a unified framework for multimodal motion generation and action streaming. UniAct enables humanoid rob
UniAct는 MLLM과 causal streaming pipeline을 결합한 두 단계 프레임워크로, 인간형 로봇이 언어, 음악, 궤적 등 다양한 multimodal 명령을 sub-500ms 지연시간으로 실행할 수 있게 한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: UniAct는 MLLM과 robust tracking을 unified framework로 통합하여 실제 humanoid robot에서 multimodal instruction following을 low latency로 달성한 의미 있는 연구이며, UA-Net 데이터셋 기여와 함께 embodied AI 분야에서 중요한 진전을 나타낸다.