Essence
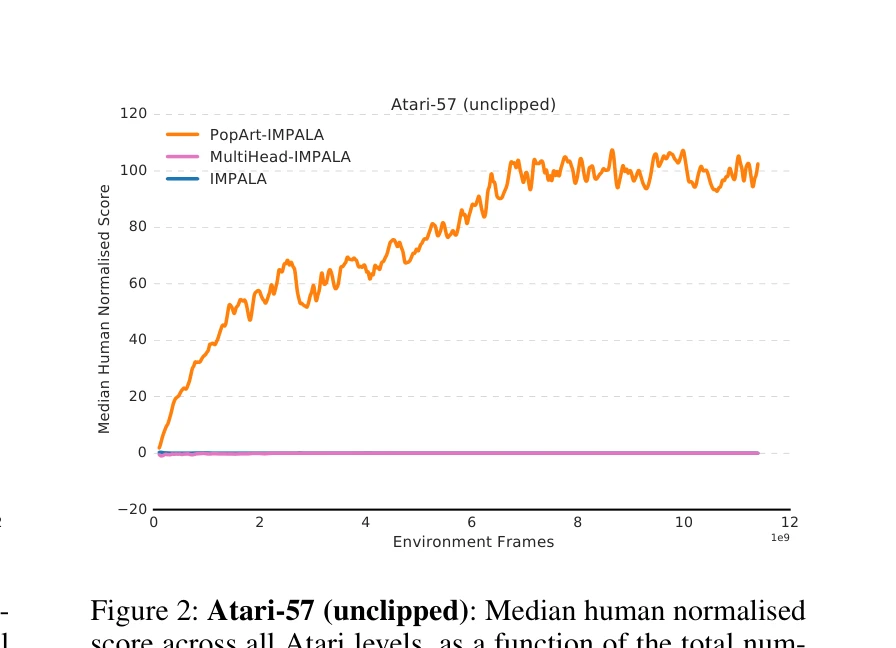
Figure 2: Atari-57 (unclipped): Median human normalised
Multi-task Deep Reinforcement Learning에서 task 간의 reward scale과 sparsity 차이로 인한 불균형 문제를 PopArt 정규화를 통해 해결하여, 57개 Atari 게임을 단일 정책으로 인간 수준 이상의 성능으로 학습.
저자: Matteo Hessel, Hubert Soyer, Lasse Espeholt, Wojciech Czarnecki, Simon Schmitt, Hado van Hasselt | 날짜: 2018-09-12 | URL: https://arxiv.org/abs/1809.04474 📄 PDF
Figure 2: Atari-57 (unclipped): Median human normalised
Multi-task Deep Reinforcement Learning에서 task 간의 reward scale과 sparsity 차이로 인한 불균형 문제를 PopArt 정규화를 통해 해결하여, 57개 Atari 게임을 단일 정책으로 인간 수준 이상의 성능으로 학습.
Figure 2: Atari-57 (unclipped): Median human normalised
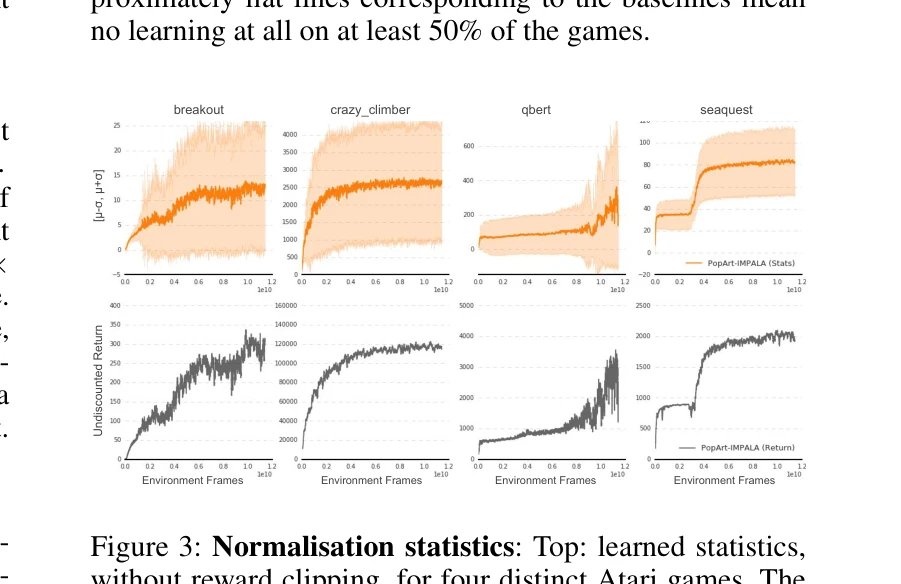
Figure 3: Normalisation statistics: Top: learned statistics,
총평: PopArt를 multi-task RL에 적용한 실용적이고 효과적인 솔루션으로, 단일 정책이 다양한 task에서 인간 수준 성능을 달성한 것은 RL 분야의 중요한 이정표다. 명확한 문제 정의, 우아한 솔루션, 그리고 강력한 실험 결과로 높은 가치의 논문이다.