저자: Liang Pan, Zeshi Yang, Zhiyang Dou, Wenjia Wang, Buzhen Huang, Bo Dai, Taku Komura, Jingbo Wang | 날짜: 2025-03-25 | URL: https://arxiv.org/abs/2503.19901 📄 PDF
Essence
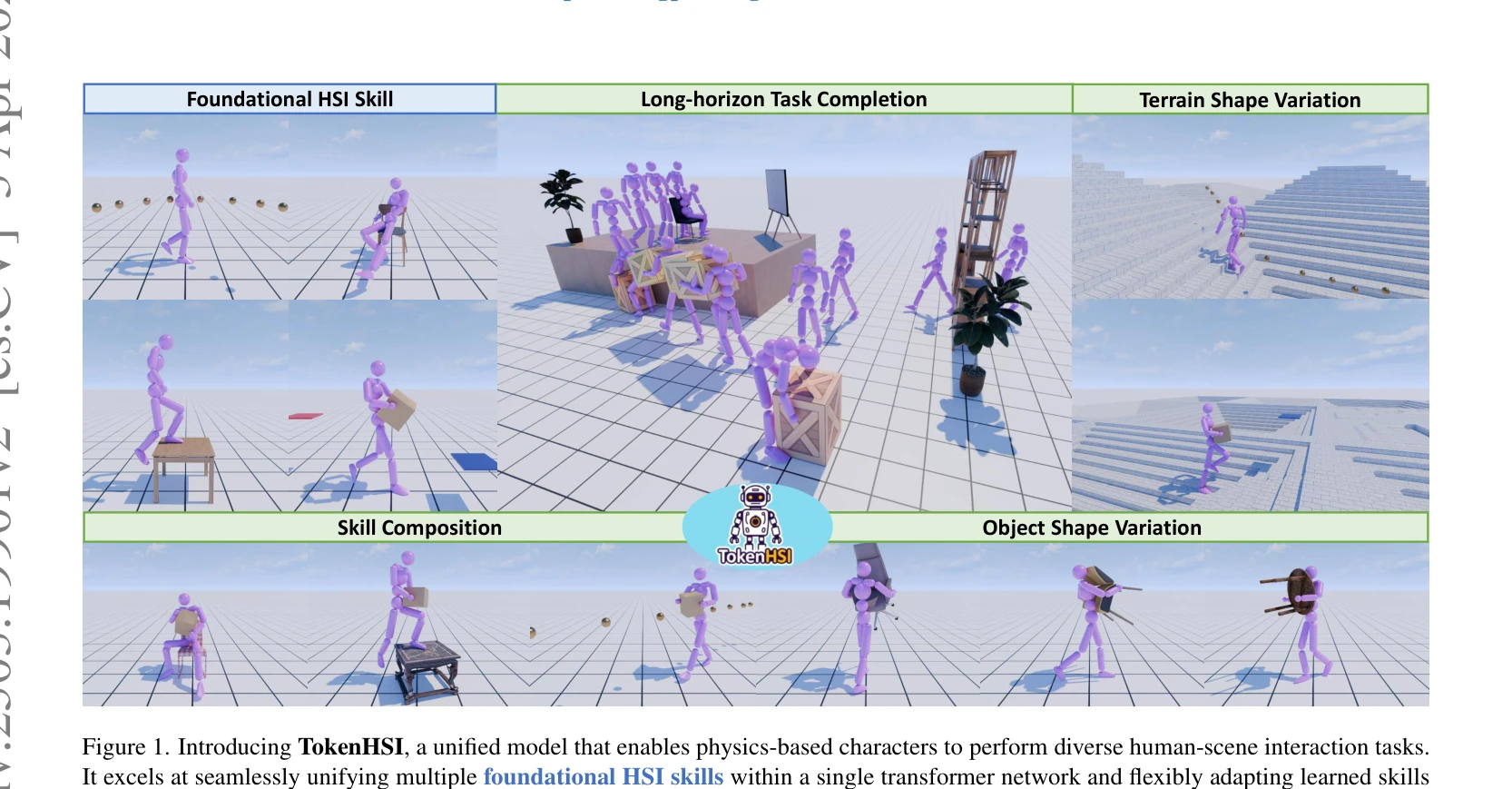
Figure 1. Introducing TokenHSI, a unified model that enables physics-based characters to perform diverse human-scene int
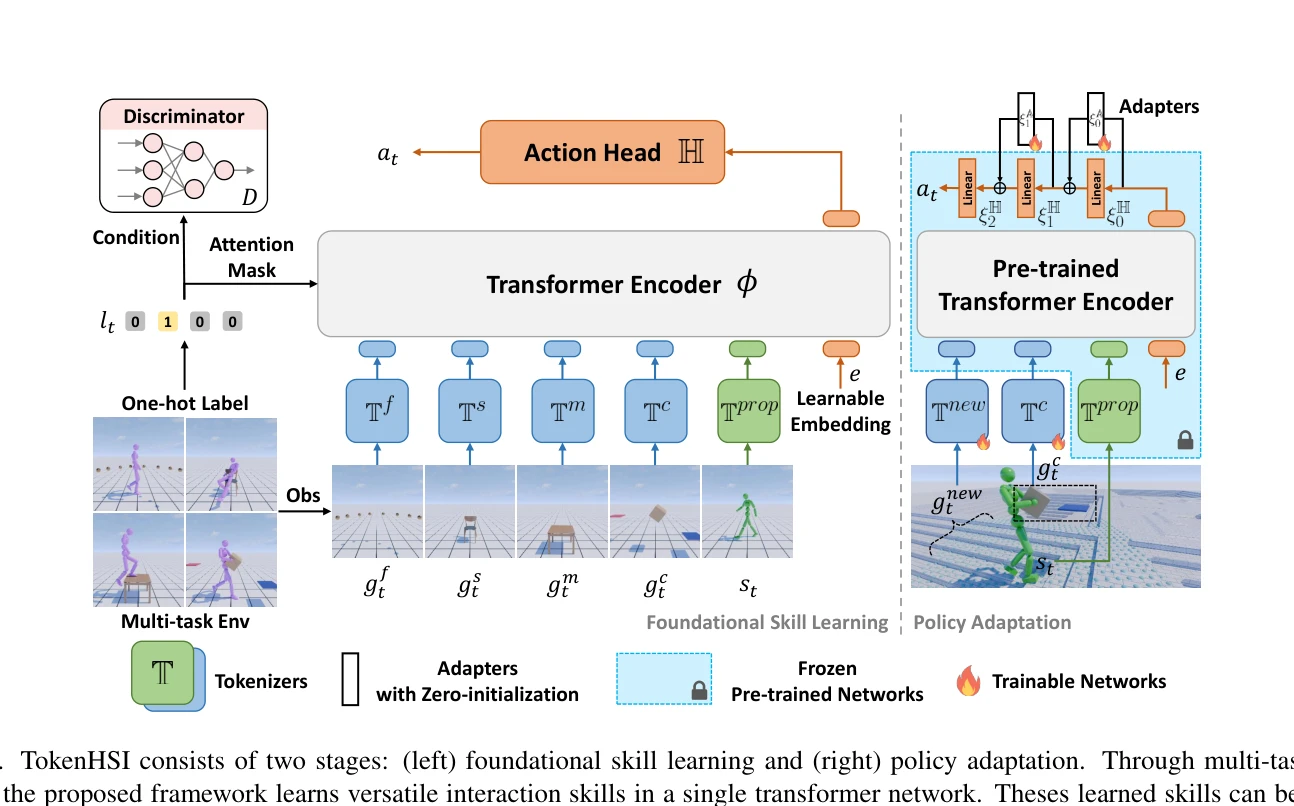
TokenHSI는 transformer 기반의 통합 정책으로 humanoid 고유감각을 공유 토큰으로 모델링하고 task 토큰과 masking mechanism으로 결합하여 다양한 인간-장면 상호작용(HSI) 기술을 단일 네트워크에서 통합한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: TokenHSI는 독립적 proprioception tokenizer와 masking mechanism을 통해 다중 HSI 기술을 단일 네트워크에서 효과적으로 통합하고, 변수 길이 입력을 활용한 효율적 정책 적응까지 실현한 혁신적인 접근법으로, 컴퓨터 애니메이션과 embodied AI 분야에서 실질적인 기여를 한다.