Essence

Figure 1: DISaM for tasks with information-seeking behavior. To make the right decision in a
로봇이 조작 작업을 수행하기 위해 필요한 정보를 능동적으로 탐색하는 문제를 factorized Contextual MDP로 정의하고, 정보 탐색 정책과 정보 활용 정책으로 분리된 dual-policy 솔루션 DISaM을 제안한다.
저자: Shivin Dass, Jiaheng Hu, Ben Abbatematteo, Peter Stone, Roberto Martín-Martín | 날짜: 2024-10-24 | URL: https://arxiv.org/abs/2410.18964 📄 PDF
Figure 1: DISaM for tasks with information-seeking behavior. To make the right decision in a
로봇이 조작 작업을 수행하기 위해 필요한 정보를 능동적으로 탐색하는 문제를 factorized Contextual MDP로 정의하고, 정보 탐색 정책과 정보 활용 정책으로 분리된 dual-policy 솔루션 DISaM을 제안한다.

Figure 4: Tasks in our evaluation of DISaM. We evaluated DISaM on 3 simulation tasks —
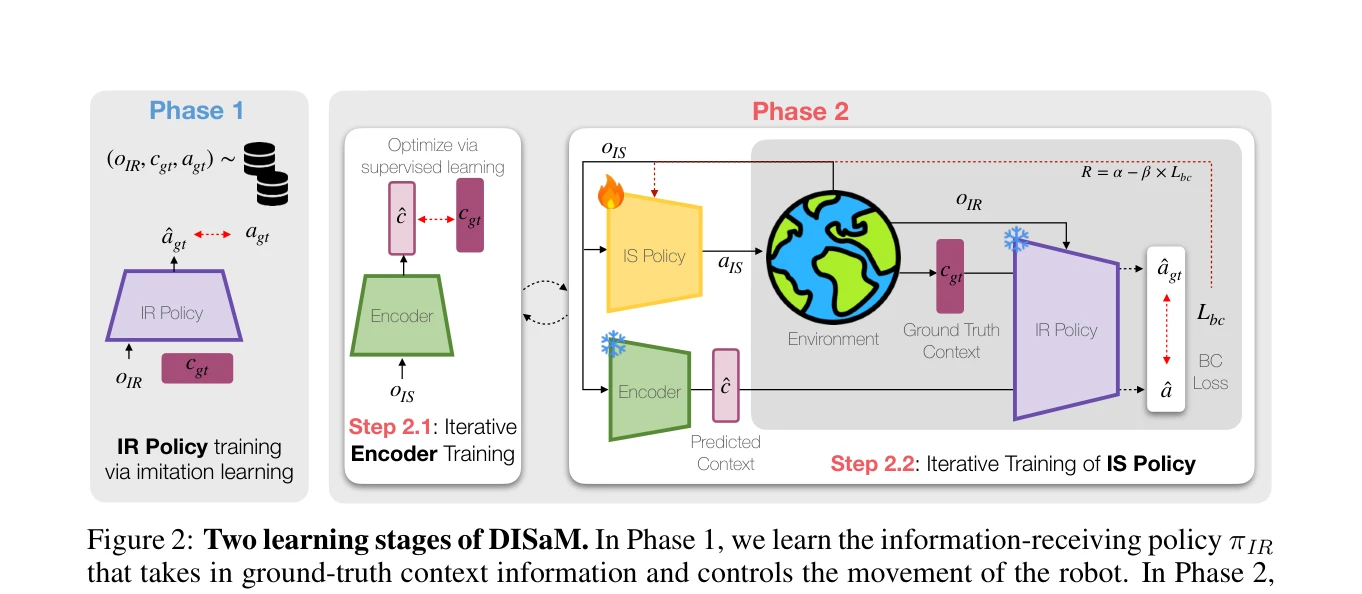
Figure 2: Two learning stages of DISaM. In Phase 1, we learn the information-receiving policy πIR
총평: 정보 탐색과 조작의 분리를 통해 장지평 POMDP를 효율적으로 해결하는 우아한 솔루션을 제시하며, 광범위한 실험 검증으로 실용성을 입증한 강력한 논문이다. 다만 다단계 탐색 최적화와 완전 자동학습 가능성 탐색이 향후 과제이다.