How
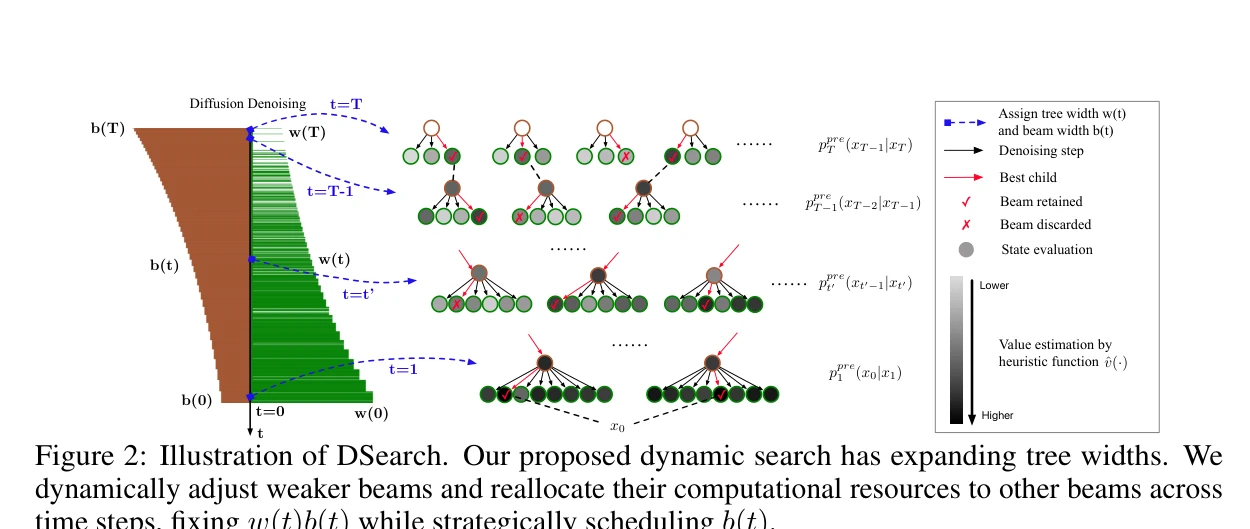
Figure 2: DSearch의 트리 너비 확장과 빔 폭 동적 조정. 약한 빔의 자원을 다른 빔으로 재할당하면서 w(t)b(t) 유지
트리 정의 및 너비 제한:
- 나이브 접근의 O(|X|^T) 복잡도를 해결하기 위해 사전학습된 정책으로부터 샘플링하여 트리 너비 w(t) 제한
- w(t)=1일 경우 best-of-N 샘플링으로 축소되는 일반적 형태 유지
휴리스틱 함수(Heuristic Function):
- 중간 노드의 가치를 평가하기 위해 추정된 가치 함수(estimated value function) 도입
- 기존의 단순 근사 ν̂_t(x_t) := r(x̂_0(x_t))를 개선하는 더 정확한 접근법 제시
룩어헤드 휴리스틱(Lookahead Heuristic):
- Algorithm 1에서 K 스텝 선점 탐색을 통해 소프트 가치 함수의 근사 정확도 향상
- 소수의 추가 시뮬레이션으로 더 신뢰할 만한 중간 노드 평가 가능
노이즈 레벨 기반 동적 스케줄링:
- 노이즈 레벨에 따라 적응적으로 트리 확장 일정 조정
- 초기 단계(높은 노이즈)에서 넓은 탐색, 후기 단계(낮은 노이즈)에서 선택적 탐색
같이 보면 좋은 논문
기반 연구
확산 모델의 추론 시간 제어와 정렬을 위한 이론적 기초를 제공한다.
기반 연구
과학 분야 LLM 및 생성형 모델 서베이는 diffusion 기반 reward fine-tuning의 발전적 맥락을 이해하는 데 이론적 기반을 제공한다.
기반 연구
Drugpilot 논문에서 파라미터화된 추론 기반의 에이전트를 제안하여, 비미분 보상 함수 최적화에 관한 방법론적 시사점을 제공합니다.
기반 연구
디퓨전 모델의 인퍼런스 시 정렬과 다중샷 일치 문제에 대한 심도 있는 분석을 제공합니다.
기반 연구
Diffusion 모델 및 테스트타임 reward alignment 관련 메커니즘이 능동학습 샘플링에 영향을 줄 수 있습니다.
다른 접근
555가 GAN 기반이라면 296은 diffusion 모델에서 inference alignment로 분자 생성 성능을 높이는 또다른 최신 접근을 소개합니다.
다른 접근
두 논문 모두 diffusion 모델의 reward 기반 보정 문제를 다루지만, 서로 다른 최적화 방식과 실험 프로토콜을 제안하여 비교 분석이 유용하다.
다른 접근
Inference-Time Alignment in Diffusion Models with Reward-Guided Search 논문은 Diffusion 모델 정렬에서 보상 기반 최적화의 또 다른 구현 사례입니다.
다른 접근
Dynamic multi-agent orchestration and retrieval 논문은 다중 에이전트 기반의 복잡한 AI 연구 작업 자동화에 중점을 두며, 코드 기반 재현성 평가와 상호보완적 접근법을 제시한다.
다른 접근
비미분 보상 함수를 위한 다른 최적화 접근법을 확산 모델에 적용한 연구이다.
다른 접근
분자 유효성 보장을 위한 다른 그래프 생성 방법론을 제시하는 대안적 연구이다
후속 연구
테스트타임 reward-guided 정렬에 대한 FMVACC 대신 iterative refinement 방식을 적용하여 실시간 최적화의 발전적 관점을 보여준다.
후속 연구
296 논문은 확산 모델의 추론 정렬 문제를 논의하여, 3029의 원자 궤적 생성 시 활용하는 통계/생성모델의 최신 기법과 연결된다.
후속 연구
동적 빔 탐색을 통한 확산 모델 정렬의 효율성 향상을 추가적으로 확장한다.