Essence
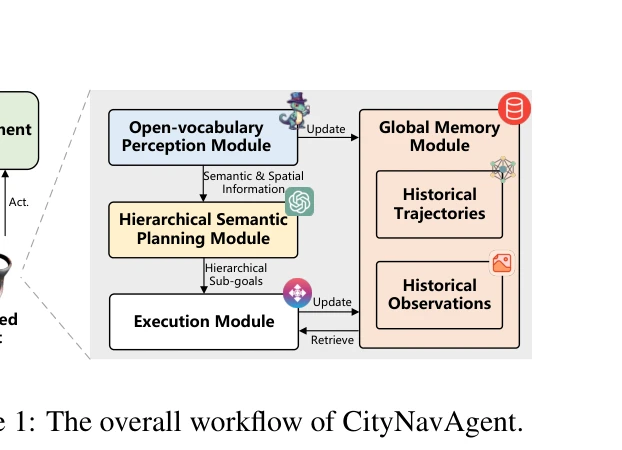
Figure 1: The overall workflow of CityNavAgent.
CityNavAgent는 계층적 의미 계획(HSPM)과 전역 메모리 모듈을 통합하여 도시 환경에서 드론이 자연어 지시를 따라 네비게이션하는 aerial VLN 작업을 수행하는 LLM 기반 에이전트이다.
저자: Weichen Zhang, Chen Gao, Shiquan Yu, Ruiying Peng, Baining Zhao, Qian Zhang, Jinqiang Cui, Xinlei Chen, Yong Li | 날짜: 2025-05-08 | URL: https://arxiv.org/abs/2505.05622 📄 PDF
Figure 1: The overall workflow of CityNavAgent.
CityNavAgent는 계층적 의미 계획(HSPM)과 전역 메모리 모듈을 통합하여 도시 환경에서 드론이 자연어 지시를 따라 네비게이션하는 aerial VLN 작업을 수행하는 LLM 기반 에이전트이다.
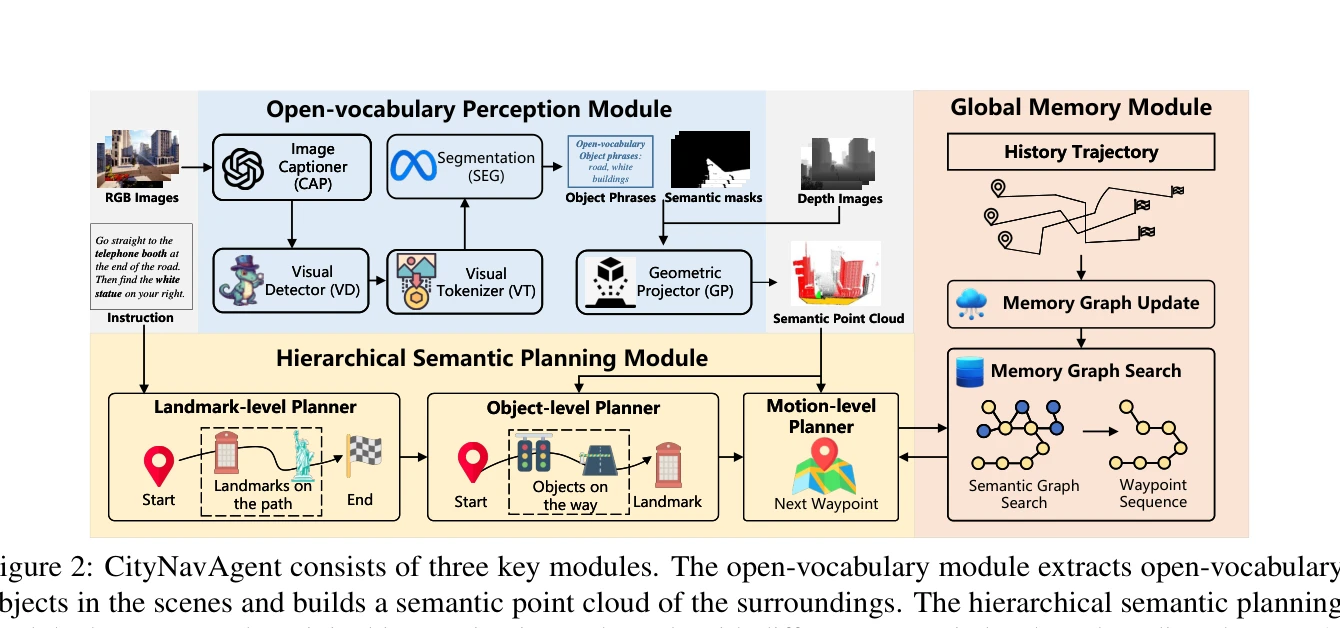
Figure 2: CityNavAgent consists of three key modules. The open-vocabulary module extracts open-vocabulary
Figure 2: CityNavAgent consists of three key modules. The open-vocabulary module extracts open-vocabulary
총평: CityNavAgent는 aerial VLN의 미해결 과제들(복잡한 도시 장면 이해, 지수적 action space)을 체계적으로 해결하는 창의적인 계층적 계획 프레임워크를 제시하며, 벤치마크에서 state-of-the-art 성능을 달성한 의미있는 연구이다. 다만 실제 드론 검증과 오류 전파 분석이 필요하다.