저자: Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, Siyuan Huang | 날짜: 2023-11-18 | URL: https://arxiv.org/abs/2311.12871 📄 PDF
Essence
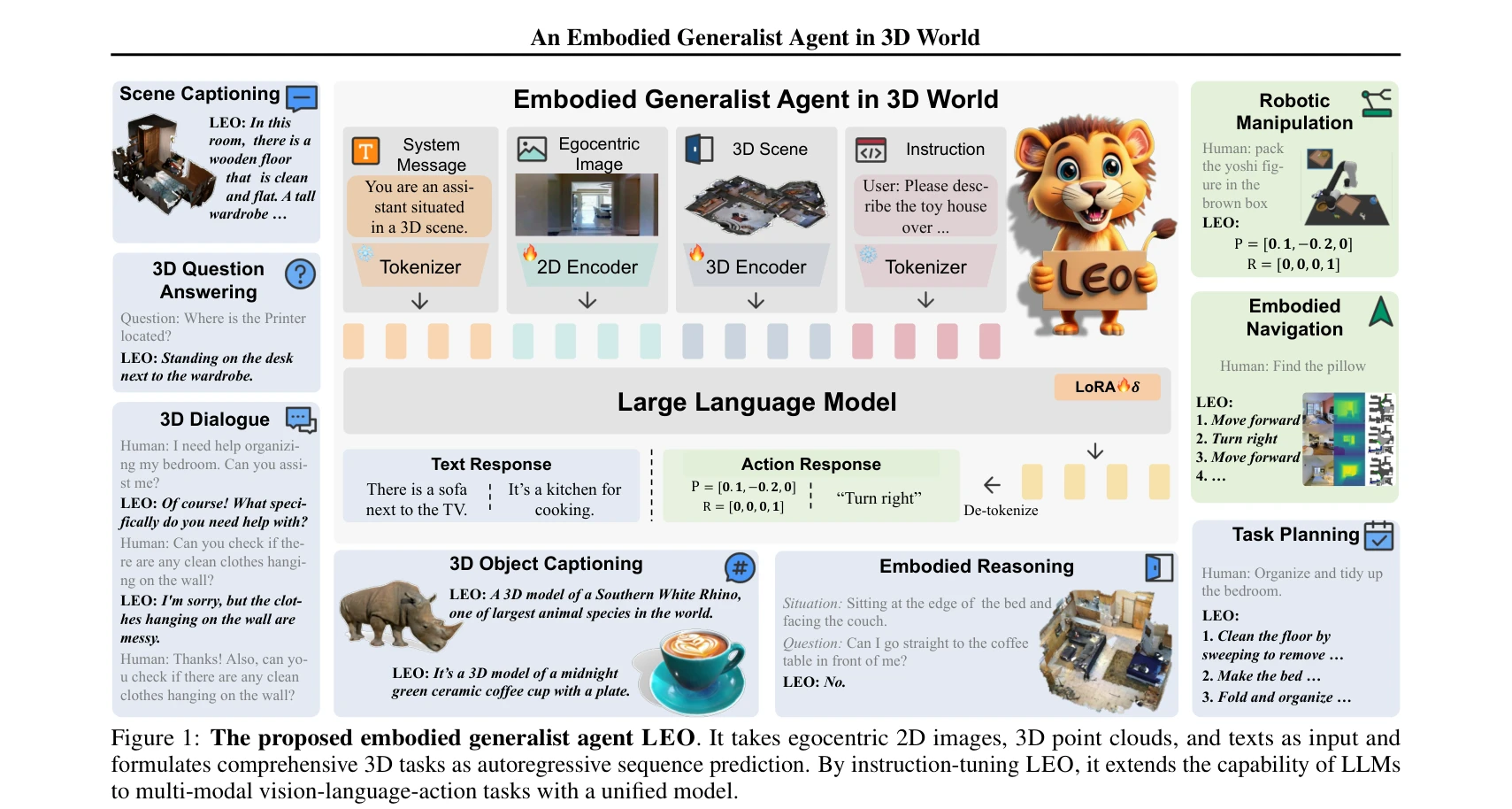
Figure 1: The proposed embodied generalist agent LEO. It takes egocentric 2D images, 3D point clouds, and texts as input
LEO는 egocentric 2D 이미지, 3D point cloud, 텍스트를 입력으로 받아 3D 환경에서 인식, grounding, 추론, 계획, 행동을 수행할 수 있는 최초의 embodied generalist agent이다. 통일된 모델 아키텍처와 학습 목표로 3D vision-language alignment와 3D vision-language-action instruction tuning의 두 단계로 학습된다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: LEO는 3D 환경에서의 embodied generalist agent 개발에 중요한 이정표를 제시하며, 통일된 아키텍처로 다양한 3D 작업을 처리할 수 있음을 입증했다. LLM-assisted 데이터 생성 파이프라인은 3D 데이터 수집의 실질적 문제를 해결하는 실용적 기여이며, 광범위한 실험과 ablation study가 연구의 신뢰성을 높인다.
