Essence

Figure 1: Illustration of our Annotated Semantic
MapNav는 Vision-and-Language Navigation에서 Annotated Semantic Map(ASM)을 메모리 표현으로 사용하여 기존의 과거 프레임 저장의 비효율성을 해결하는 end-to-end VLM 기반 모델이다. ASM은 top-down 시멘틱 맵에 텍스트 라벨을 추가하여 구조화된 내비게이션 정보를 제공한다.
저자: Lingfeng Zhang, Xiaoshuai Hao, Qinwen Xu, Qiang Zhang, Xinyao Zhang, Pengwei Wang, Jing Zhang, Zhongyuan Wang, Shanghang Zhang, Renjing Xu | 날짜: 2025-02-19 | URL: https://arxiv.org/abs/2502.13451 📄 PDF
Figure 1: Illustration of our Annotated Semantic
MapNav는 Vision-and-Language Navigation에서 Annotated Semantic Map(ASM)을 메모리 표현으로 사용하여 기존의 과거 프레임 저장의 비효율성을 해결하는 end-to-end VLM 기반 모델이다. ASM은 top-down 시멘틱 맵에 텍스트 라벨을 추가하여 구조화된 내비게이션 정보를 제공한다.
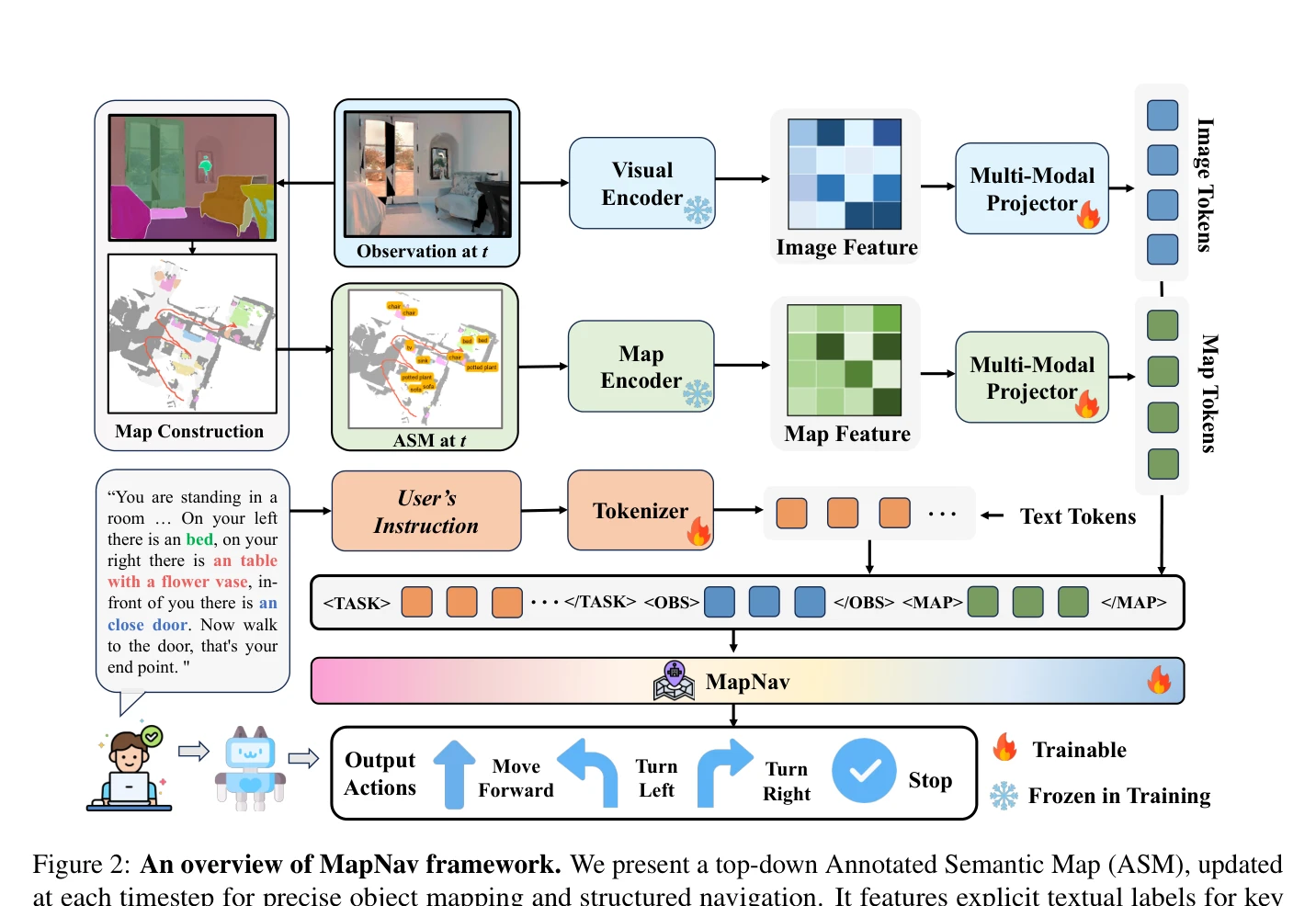
Figure 2: An overview of MapNav framework. We present a top-down Annotated Semantic Map (ASM), updated
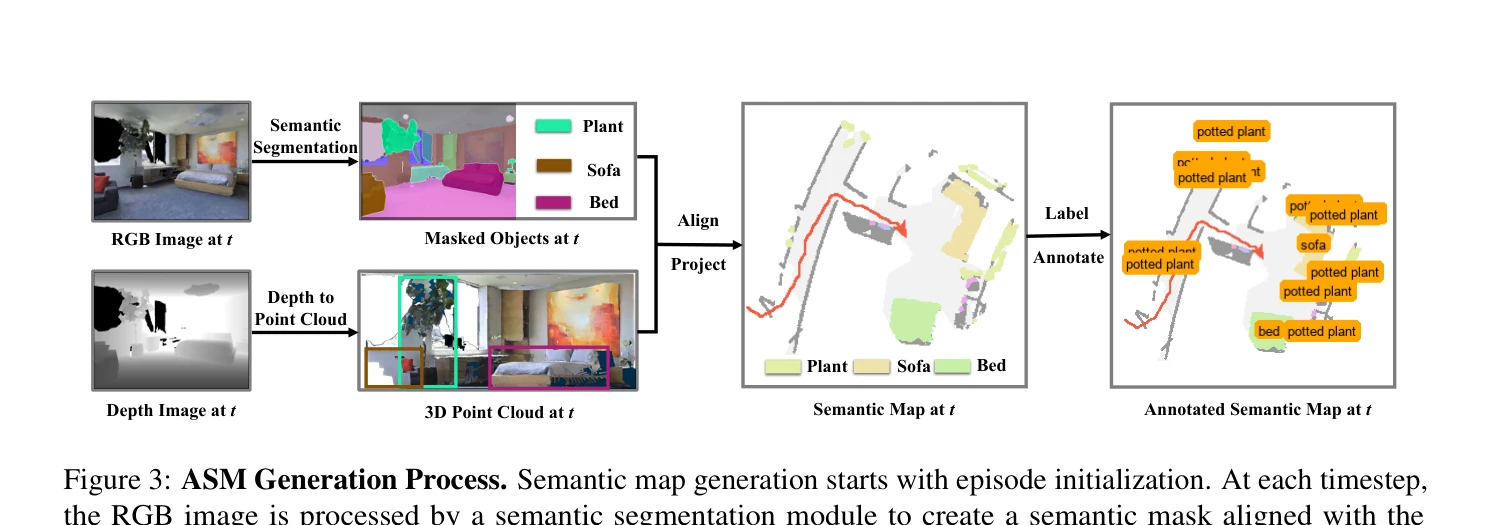
Figure 3: ASM Generation Process. Semantic map generation starts with episode initialization. At each timestep,
총평: MapNav는 Annotated Semantic Map이라는 혁신적 메모리 표현을 통해 VLN의 효율성과 구조화된 공간 이해를 동시에 달성한 견고한 연구이다. SOTA 성능 달성과 데이터셋 공개 약속으로 임체AI 커뮤니티에 실질적인 기여를 제시하며, VLN 분야의 새로운 방향을 제안한다.