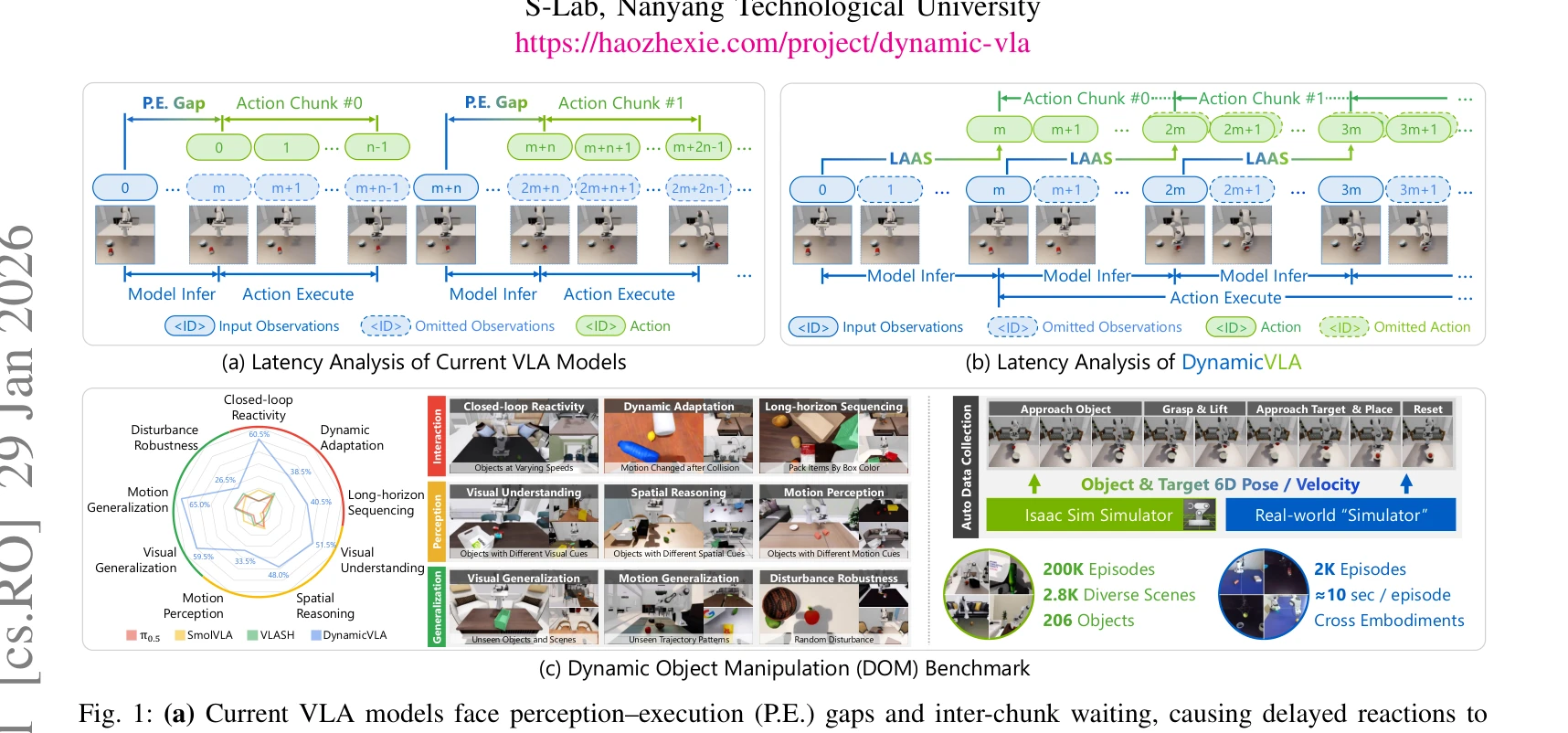
Essence
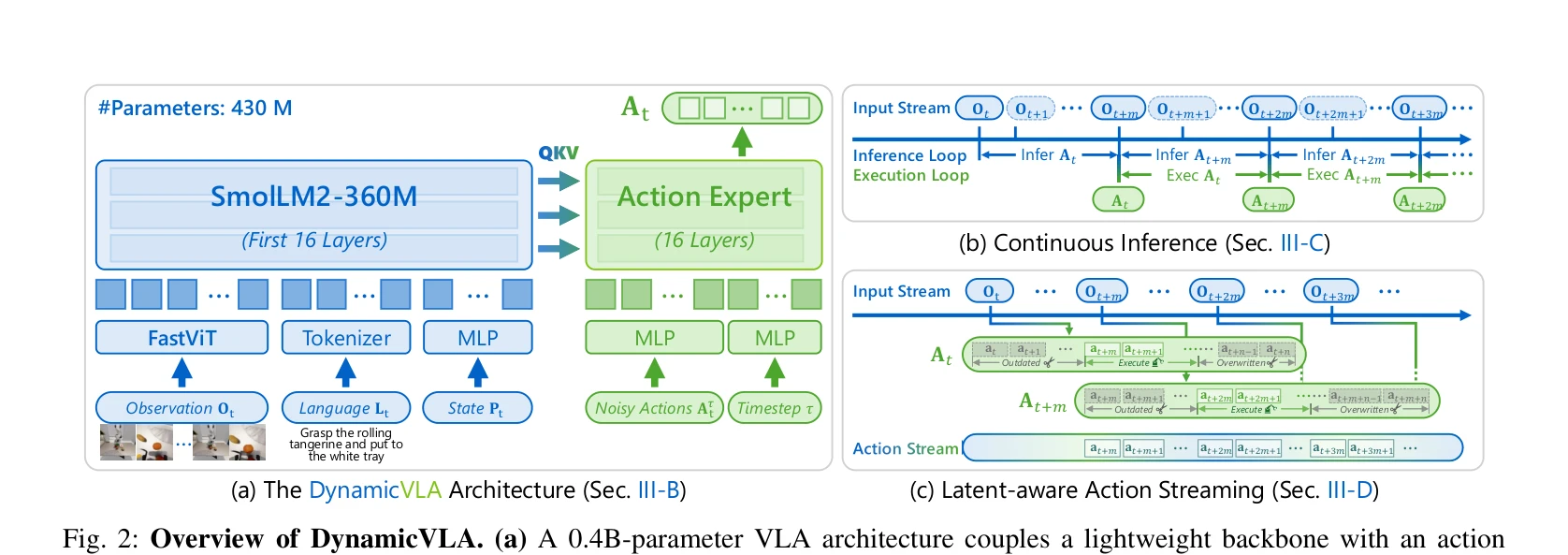
Fig. 2: Overview of DynamicVLA. (a) A 0.4B-parameter VLA architecture couples a lightweight backbone with an action
DynamicVLA는 동적 객체 조작을 위한 compact 0.4B VLA 모델로, Continuous Inference와 Latent-aware Action Streaming을 통해 지각-실행 간의 지연을 제거하고 실시간 폐루프 제어를 가능하게 한다.