저자: Zhiying Du, Bei Liu, Yaobo Liang, Yichao Shen, Haidong Cao, Xiangyu Zheng, Zhiyuan Feng, Zuxuan Wu, Jiaolong Yang, Yu-Gang Jiang | 날짜: 2025-12-05 | URL: https://arxiv.org/abs/2512.05693 📄 PDF
Essence
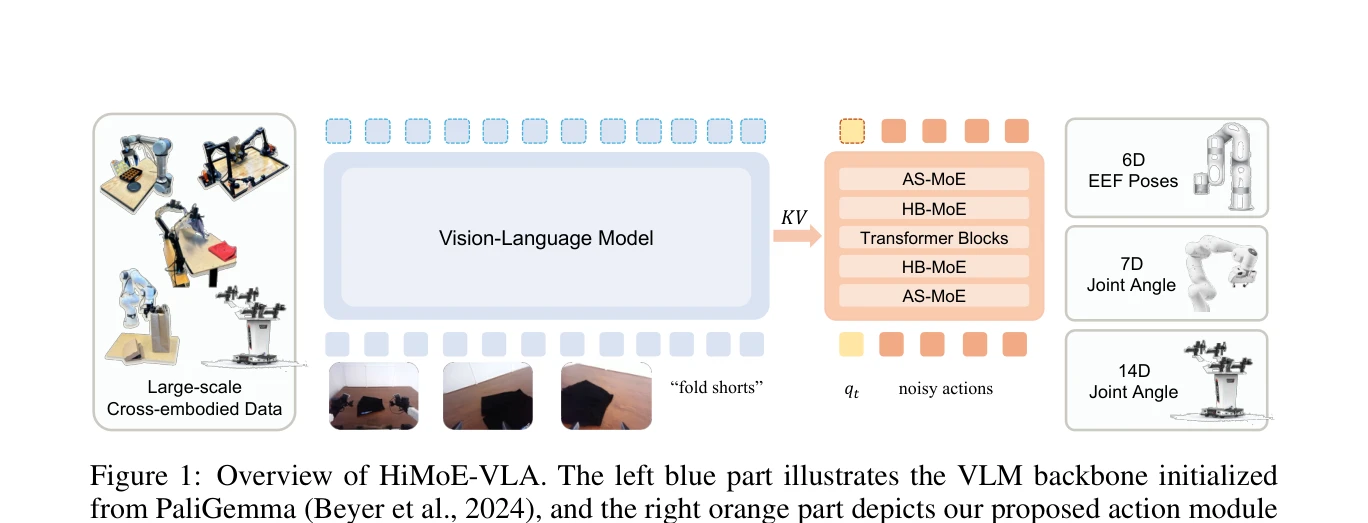
Figure 1: Overview of HiMoE-VLA. The left blue part illustrates the VLM backbone initialized
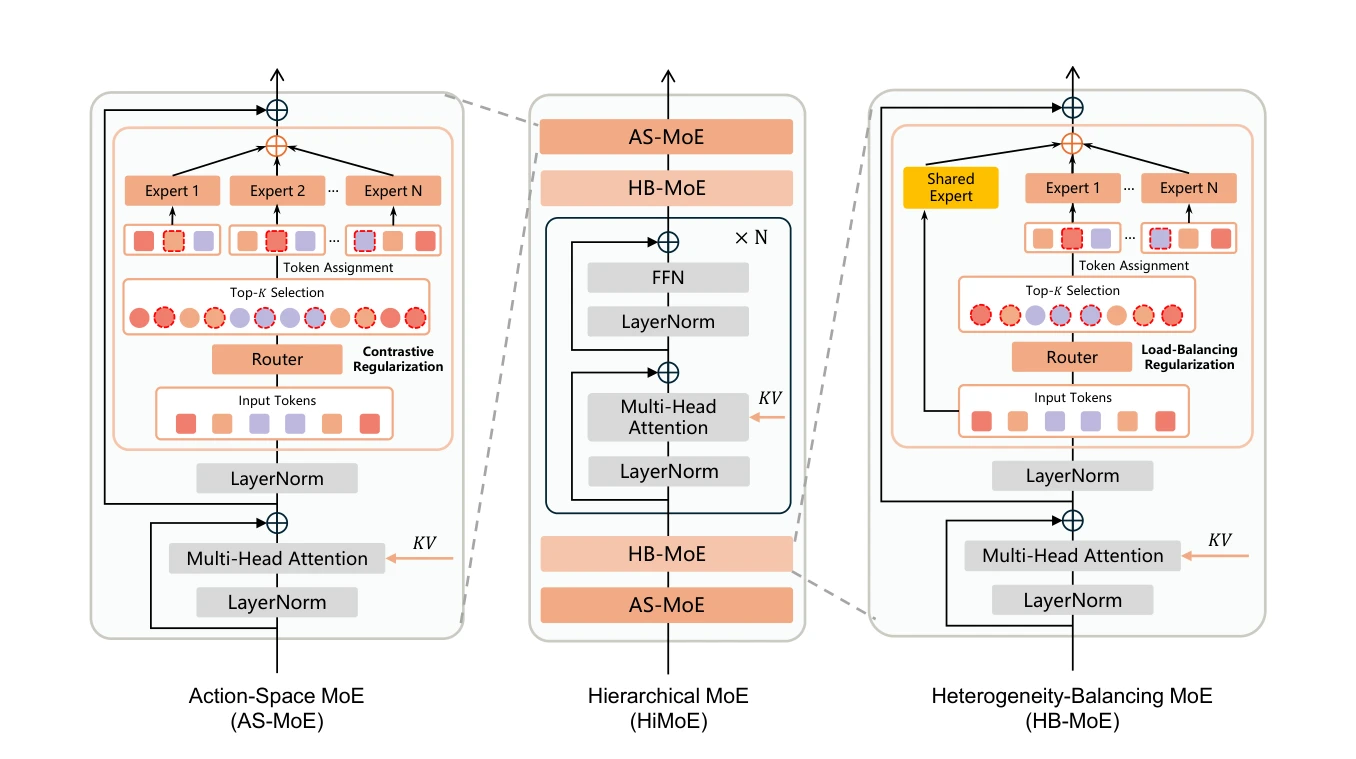
HiMoE-VLA는 로봇 데이터의 이질성(action space, embodiment, sensor configuration 등)을 명시적으로 처리하기 위해 계층적 Mixture-of-Experts 아키텍처를 제안하는 Vision-Language-Action 프레임워크이다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: HiMoE-VLA는 로봇 데이터의 본질적 이질성을 명시적으로 다루는 계층적 MoE 설계로 VLA 분야에 의미 있는 기여를 하며, 광범위한 실험을 통해 기존 방법 대비 향상된 성능과 일반화 능력을 입증한 우수한 연구이다.