저자: Guanxing Lu, Wenkai Guo, Chubin Zhang, Yuheng Zhou, Haonan Jiang, Zifeng Gao, Yansong Tang, Ziwei Wang | 날짜: 2025-05-24 | URL: https://arxiv.org/abs/2505.18719 📄 PDF
Essence
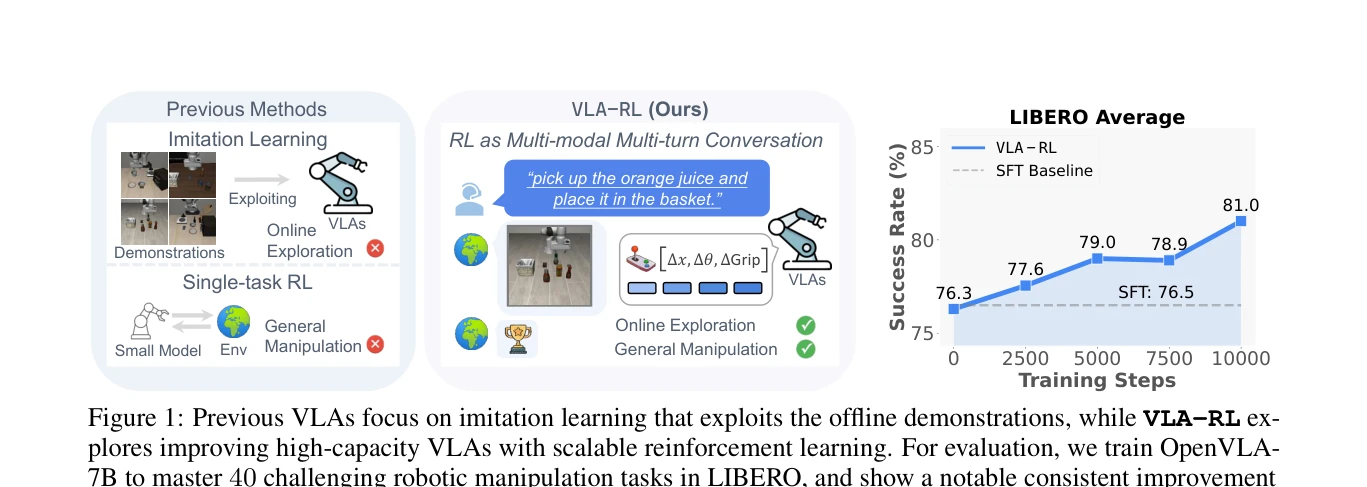
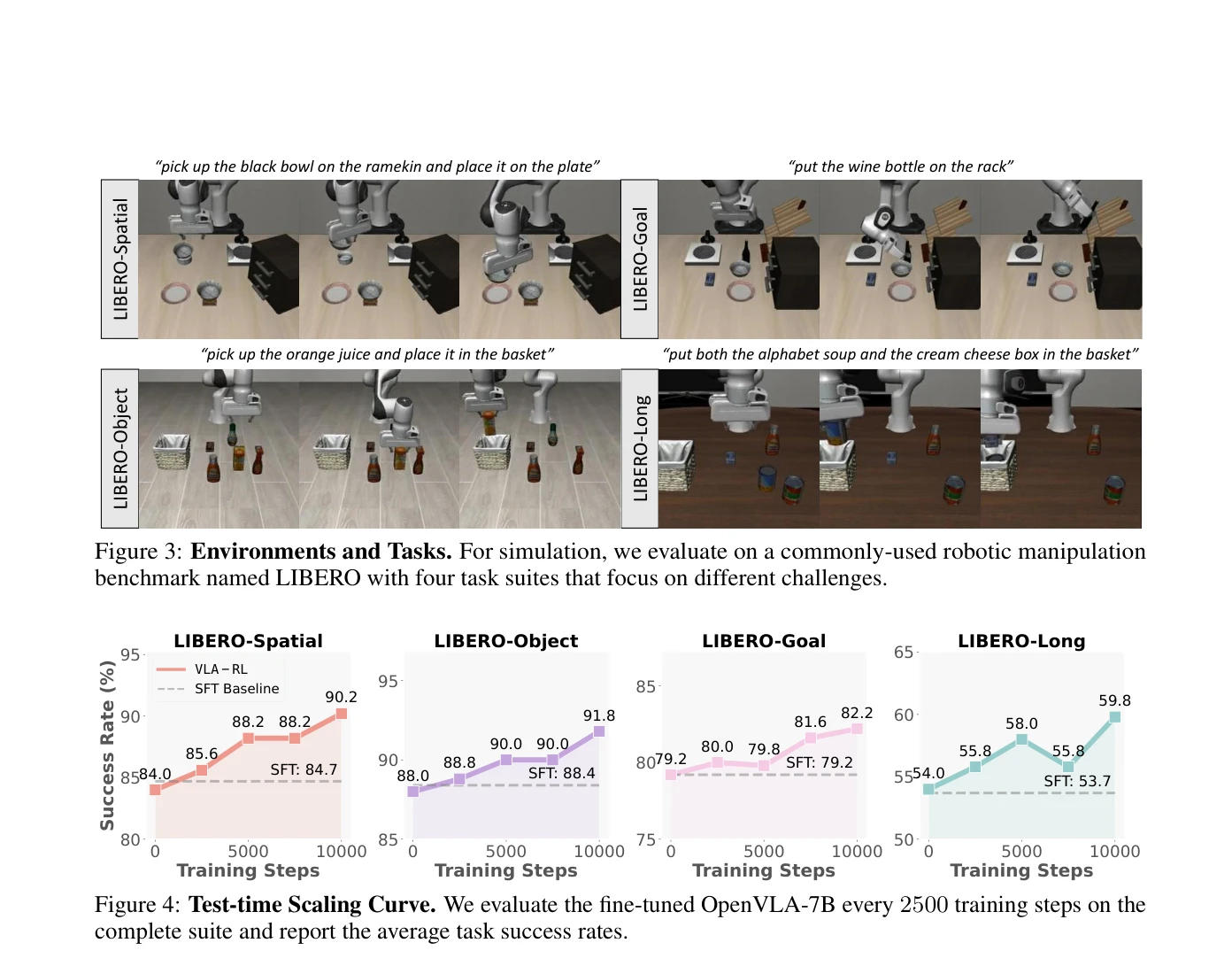
Figure 1: Previous VLAs focus on imitation learning that exploits the offline demonstrations, while VLA-RL ex-
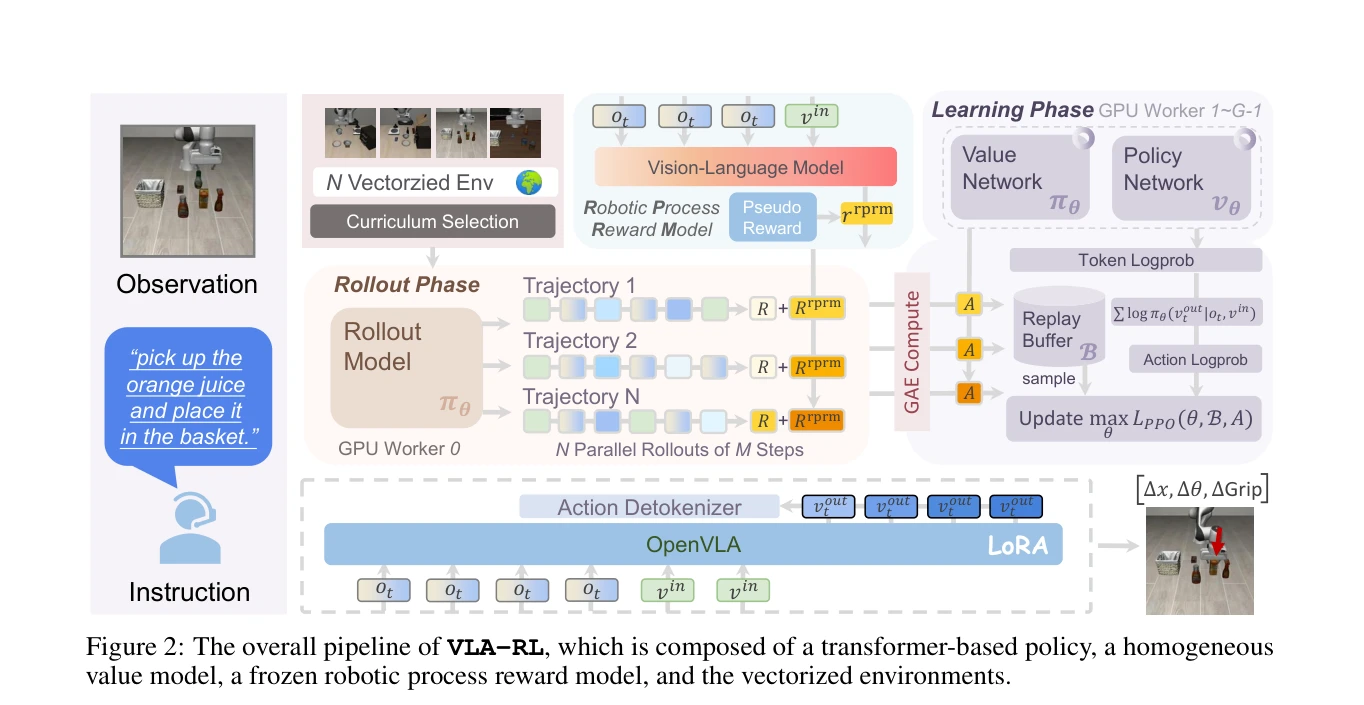
본 논문은 사전학습된 Vision-Language-Action(VLA) 모델을 강화학습(RL)으로 개선하여 로봇 조작 작업의 분포 외(OOD) 시나리오 대응력을 향상시키는 VLA-RL 프레임워크를 제시한다. 궤적 수준의 RL 공식화와 robotic process reward model을 통해 LIBERO 벤치마크에서 OpenVLA-7B의 성능을 4.5% 향상시킨다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM RL의 성공 사례를 로봇 도메인으로 창의적으로 확장하여 대규모 VLA 모델의 온라인 학습을 가능하게 하는 체계적인 프레임워크를 제시한다. LIBERO에서의 의미 있는 성능 향상과 테스트 타임 스케일링 증거는 로봇 학습의 새로운 방향을 제시하지만, 실물 로봇 검증이 필요하다.