DexGraspVLA: A Vision-Language-Action Framework Towards General Dexterous Grasping
저자: Yifan Zhong, Xuchuan Huang, Ruochong Li, Ceyao Zhang, Zhang Chen, Tianrui Guan, Fanlian Zeng, Ka Num Lui, Yuyao Ye, Yitao Liang, Yaodong Yang, Yuanpei Chen | 날짜: 2025-02-28 | URL: https://arxiv.org/abs/2502.20900📄 PDF
Essence
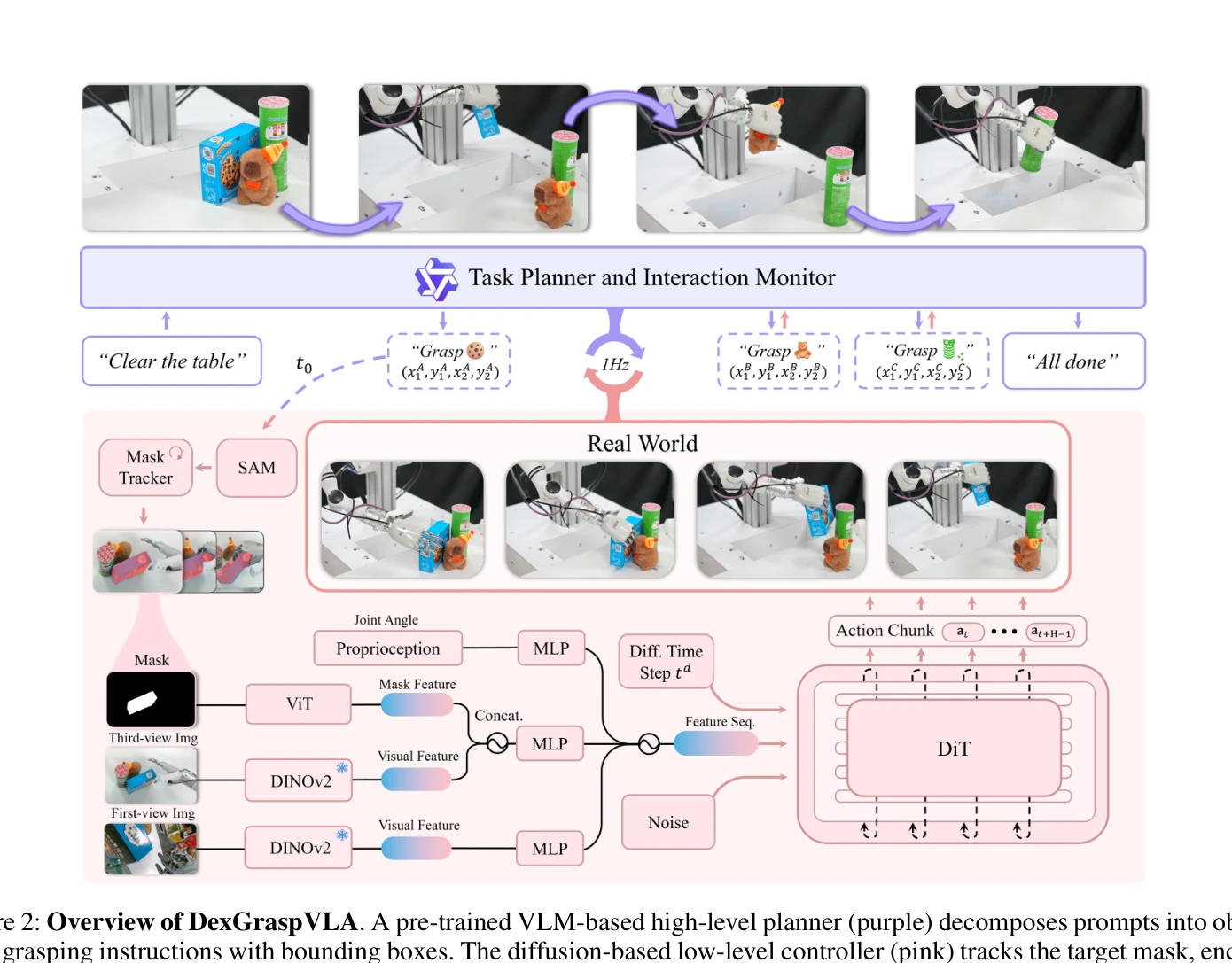
Figure 2: Overview of DexGraspVLA. A pre-trained VLM-based high-level planner (purple) decomposes prompts into object-
DexGraspVLA는 Vision-Language model을 고수준 계획자로, diffusion 기반 저수준 행동 컨트롤러를 학습하는 계층적 VLA 프레임워크로, foundation model을 통해 언어·시각 입력을 도메인 불변 표현으로 변환하여 모방 학습의 일반화를 달성한다.
Motivation
Known: Dexterous grasping은 로봇 조작의 기본 과제이나, 기존 연구는 단일 객체 또는 제한된 환경 가정에 의존하며 일반화 성능이 제약적이다. Foundation model은 인터넷 규모 데이터로 학습되어 우수한 일반화 능력을 보유하지만, 로봇 정책에 직접 적용 시 대규모 시연 데이터를 요구하고 unseen scenario에서 성능 저하가 발생한다.
Gap: Foundation model의 우수한 일반화 능력과 모방 학습의 제한된 데이터 활용성을 결합하여, 도메인 시프트 완화를 통해 폐루프 제어 정책의 강건한 일반화를 달성하는 방법이 부족하다. 특히 cluttered scenario에서의 장기 지평 다중 객체 grasping과 adversarial robustness를 동시에 달성하는 통합 프레임워크가 부재하다.
Why: 실세계 로봇 응용은 다양한 객체 물리 특성, 환경 변동(조명, 배경), 방해 조건에서 견고한 grasping 능력을 요구하며, 제한된 전문가 데이터로부터 효과적인 일반화 달성은 실용적 배포의 핵심 과제이다.
Approach: DexGraspVLA는 사전학습 VLM을 고수준 계획자로 활용하여 도메인 불변 affordance 신호를 생성하고, 저수준 컨트롤러는 vision foundation model로 multimodal 입력을 정제한 후 diffusion 기반 action head로 폐루프 행동을 생성하는 계층적 구조를 채택한다.
Achievement
Figure 1: We propose DexGraspVLA, a hierarchical VLA
총평: DexGraspVLA는 foundation model과 imitation learning의 상보적 강점을 계층적으로 통합하여 cluttered real-world scenario에서 unprecedented 90+% 일반화 성능을 달성한 의미 있는 기여이며, 장기 task, adversarial robustness, failure recovery를 동시 달성함으로써 실용적 dexterous grasping 로봇의 실현 가능성을 크게 높였다.