저자: Yi Zhang, Qiang Zhang, Xiaozhu Ju, Zhaoyang Liu, Jilei Mao, Jingkai Sun, Jintao Wu, Shixiong Gao, Shihan Cai, Zhiyuan Qin, Linkai Liang, Jiaxu Wang, Yiqun Duan, Jiahang Cao, Renjing Xu, Jian Tang | 날짜: 2025-03-14 | URL: https://arxiv.org/abs/2503.11089 📄 PDF
Essence
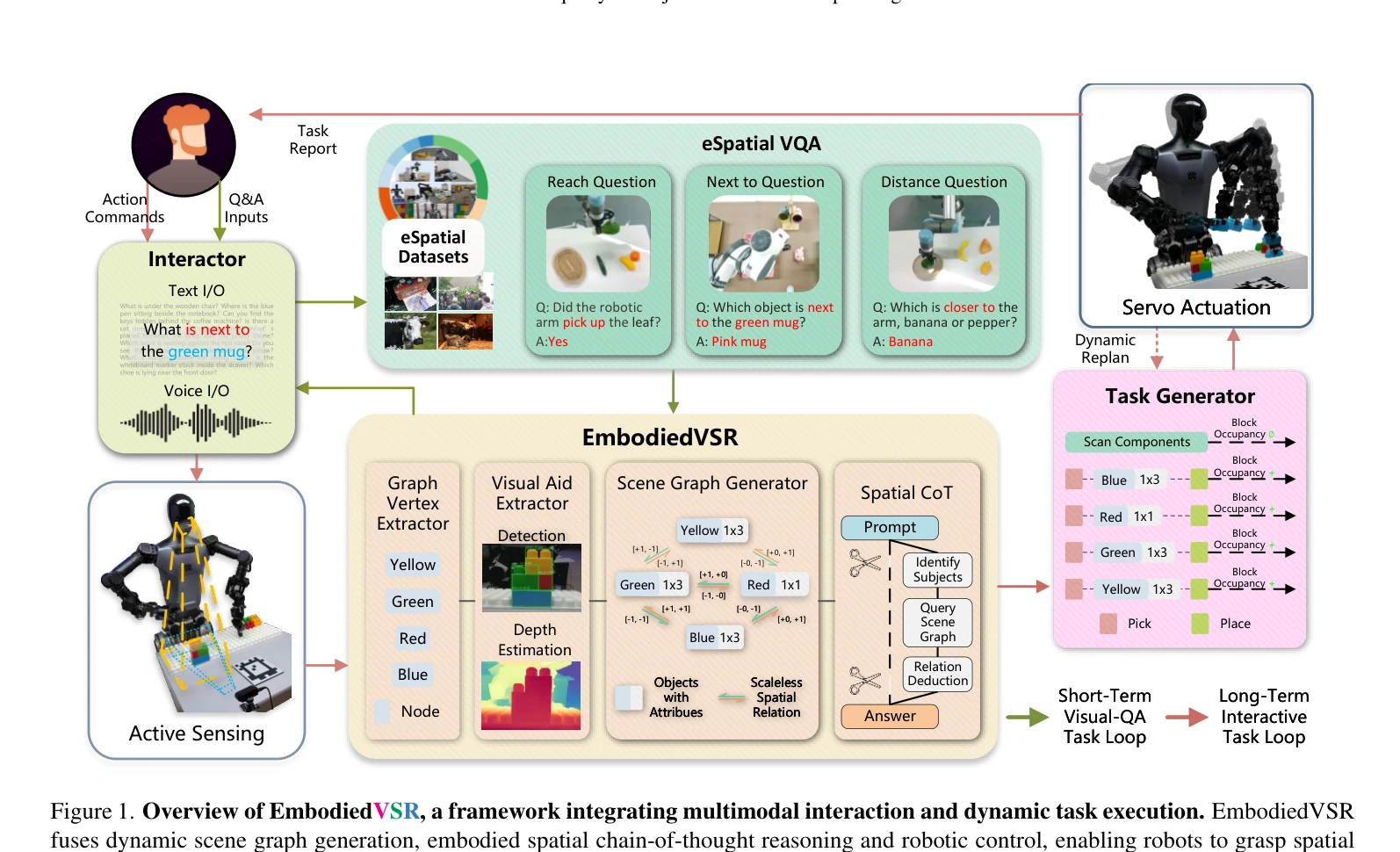
Figure 1. Overview of EmbodiedVSR, a framework integrating multimodal interaction and dynamic task execution. EmbodiedVS
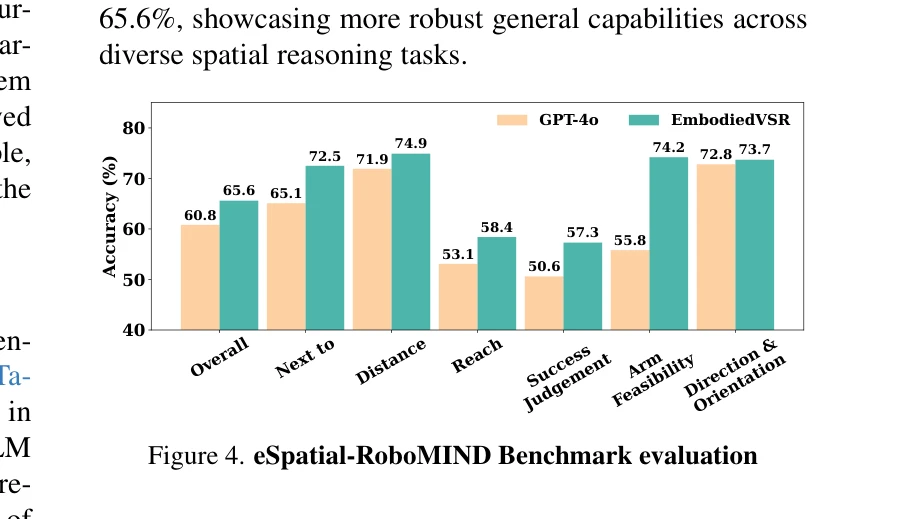
EmbodiedVSR는 동적 scene graph와 Chain-of-Thought 추론을 결합하여 embodied agent의 공간 추론 능력을 향상시키는 프레임워크이며, 이를 평가하기 위해 eSpatial-Benchmark 데이터셋을 제시한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 MLLMs을 embodied intelligence에 적용하기 위해 동적 scene graph와 structured reasoning을 결합한 혁신적 접근법을 제시하며, 새로운 벤치마크와 함께 zero-shot 공간 추론에서 유의미한 성능 개선을 달성했다. 해석 가능성과 실용성 면에서 embodied AI 분야에 중요한 기여를 할 것으로 판단된다.