Essence

Figure 1: Comparison between EmbSpatial-Bench and
Large Vision-Language Model(LVLM)들의 구현화된 환경에서의 공간 이해 능력을 평가하기 위해 egocentric 관점의 6가지 공간 관계를 포함하는 EmbSpatial-Bench 벤치마크를 구축하고, 이를 개선하기 위한 instruction-tuning 데이터셋 EmbSpatial-SFT를 제시한다.
저자: Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, Zhongyu Wei | 날짜: 2024-06-09 | URL: https://arxiv.org/abs/2406.05756 📄 PDF
Figure 1: Comparison between EmbSpatial-Bench and
Large Vision-Language Model(LVLM)들의 구현화된 환경에서의 공간 이해 능력을 평가하기 위해 egocentric 관점의 6가지 공간 관계를 포함하는 EmbSpatial-Bench 벤치마크를 구축하고, 이를 개선하기 위한 instruction-tuning 데이터셋 EmbSpatial-SFT를 제시한다.
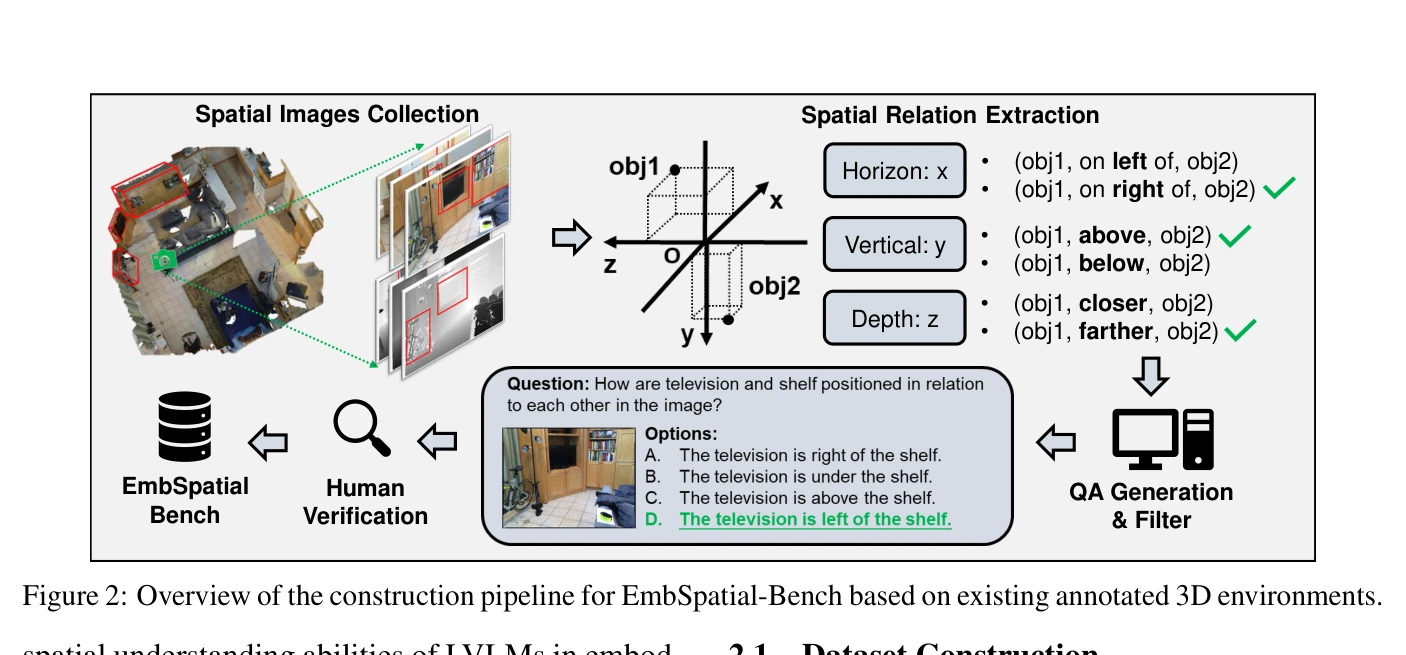
Figure 2: Overview of the construction pipeline for EmbSpatial-Bench based on existing annotated 3D environments.
Figure 2: Overview of the construction pipeline for EmbSpatial-Bench based on existing annotated 3D environments.
총평: 본 논문은 embodied AI의 핵심 능력인 spatial understanding을 체계적으로 평가하기 위해 egocentric 관점의 벤치마크를 처음으로 제시하며, 3D 환경 기반의 자동 구축 파이프라인과 개선 데이터셋을 통해 현재 LVLM의 명확한 부족함을 드러내고 개선 방향을 제시한다는 점에서 embodied AI 커뮤니티에 중요한 기여를 한다.