저자: Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, Xuelong Li | 날짜: 2025-01-27 | URL: https://arxiv.org/abs/2501.15830 📄 PDF
Essence
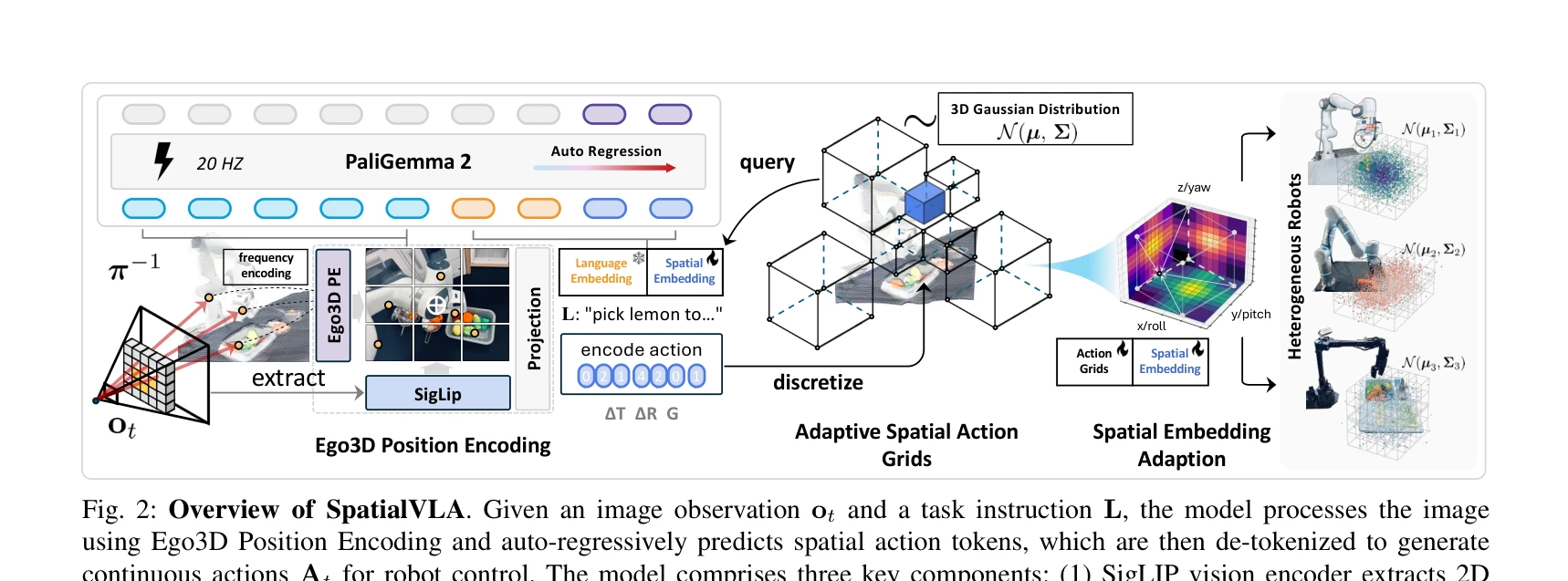
Fig. 2: Overview of SpatialVLA. Given an image observation ot and a task instruction L, the model processes the image
로봇 조작을 위한 3D 공간 이해를 강화한 VLA 모델 SpatialVLA를 제안하며, Ego3D Position Encoding과 Adaptive Action Grids를 통해 이질적인 로봇 간 일반화 가능한 공간 표현을 학습한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 VLA 모델에 체계적인 3D 공간 이해를 도입하고 이질적 로봇 간 일반화를 달성한 중요한 기여를 제시하며, 광범위한 실험을 통해 제안 방법의 효과를 입증했으나, 카메라 의존성과 이산화 해상도 제약 등의 한계가 존재한다.
