저자: Siyuan Huang, Liliang Chen, Pengfei Zhou, Shengcong Chen, Zhengkai Jiang, Yue Hu, Yue Liao, Peng Gao, Hongsheng Li, Maoqing Yao, Guanghui Ren | 날짜: 2025-01-03 | URL: https://arxiv.org/abs/2501.01895 📄 PDF
Essence
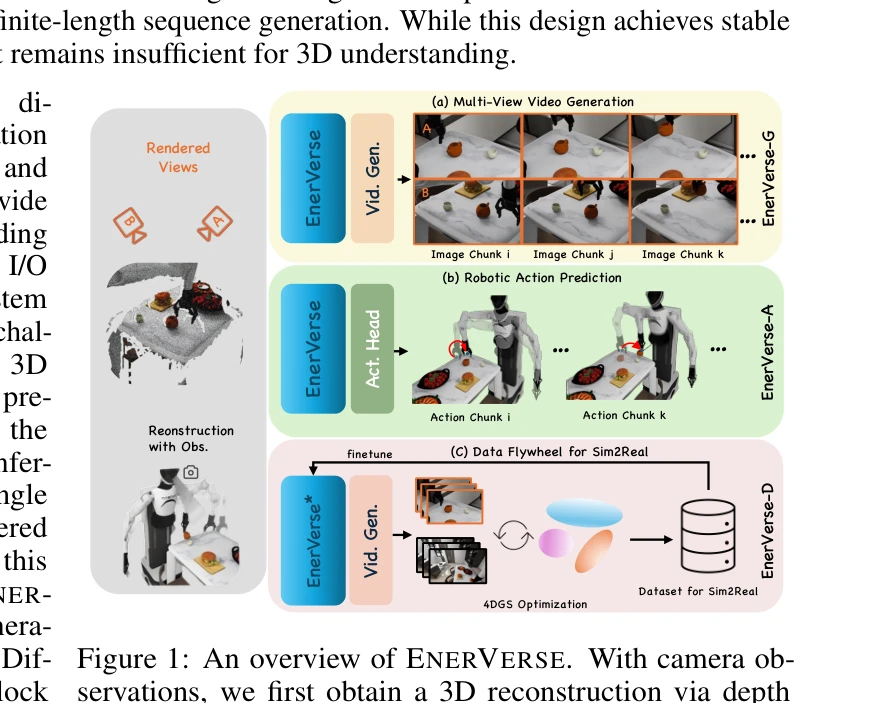
Figure 1: An overview of ENERVERSE. With camera ob-
EnerVerse는 chunk-wise autoregressive video diffusion과 sparse memory를 활용하여 instruction으로부터 embodied future space를 예측하고, multi-view video generation과 4D Gaussian Splatting 기반 data flywheel을 통해 로봇 조작을 위한 generative foundation model을 제시한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: EnerVerse는 video diffusion을 로봇 조작에 체계적으로 align하면서 3D spatial prior 학습과 data flywheel을 통해 sim-to-real gap을 해결하는 포괄적인 framework를 제시하며, chunk-wise autoregressive와 sparse memory 설계는 독창적이고 실용적이다.