저자: Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, Tao Kong | 날짜: 2023-12-20 | URL: https://arxiv.org/abs/2312.13139 📄 PDF
Essence
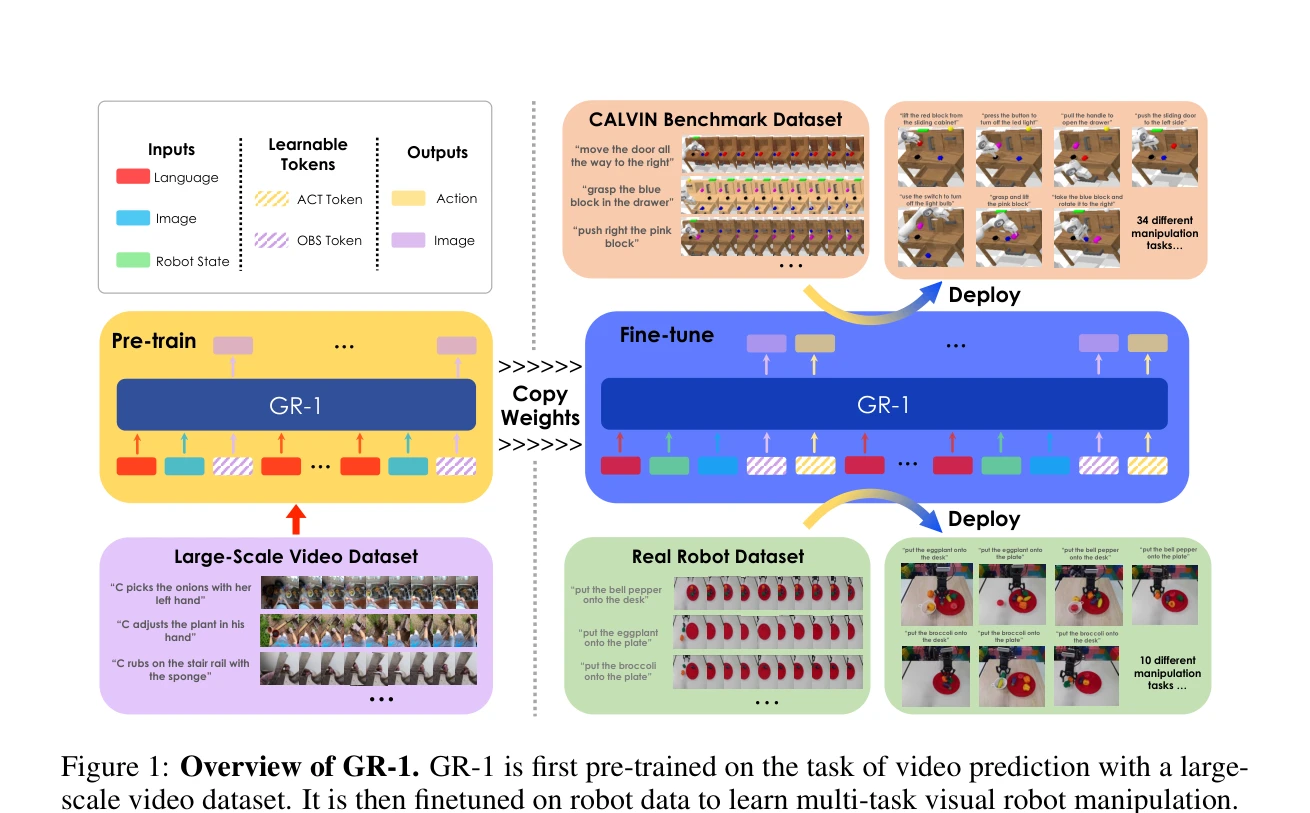
Figure 1: Overview of GR-1. GR-1 is first pre-trained on the task of video prediction with a large-
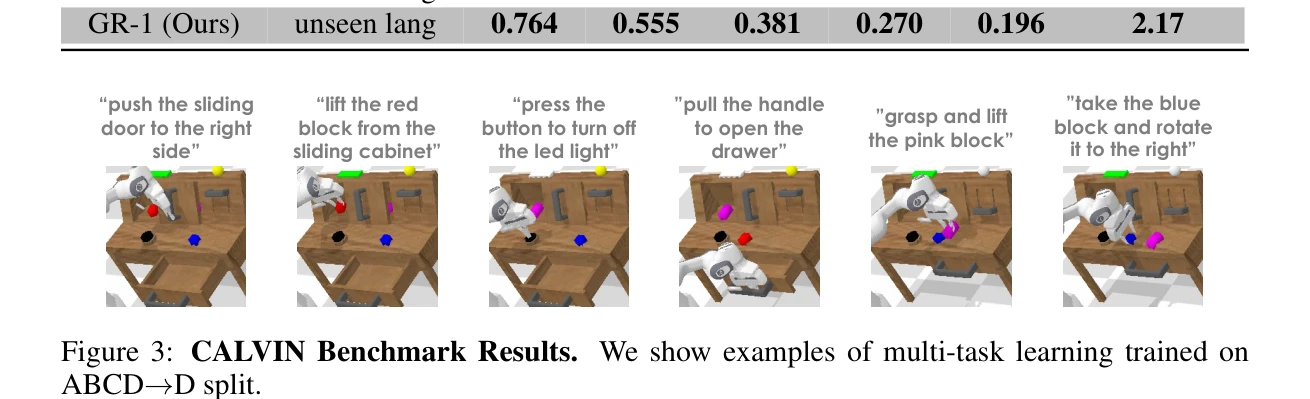
GR-1은 대규모 비디오 생성 사전학습을 활용하여 멀티태스크 언어-조건부 시각 로봇 조작을 학습하는 GPT-스타일 transformer 모델이다. 로봇은 언어 지시, 관찰 이미지, 로봇 상태를 입력받아 로봇 액션과 미래 이미지를 end-to-end 방식으로 예측한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: GR-1은 대규모 비디오 생성 사전학습을 로봇 조작에 적용하여 뛰어난 성능과 일반화 능력을 보인 의미 있는 연구이다. Unified GPT-스타일 아키텍처의 단순성과 CALVIN 벤치마크에서의 우수한 성과, 그리고 실제 로봇에서의 검증이 강점이며, 로봇 학습에서 생성 모델의 가능성을 처음으로 체계적으로 입증했다는 점에서 가치 있다.