Essence
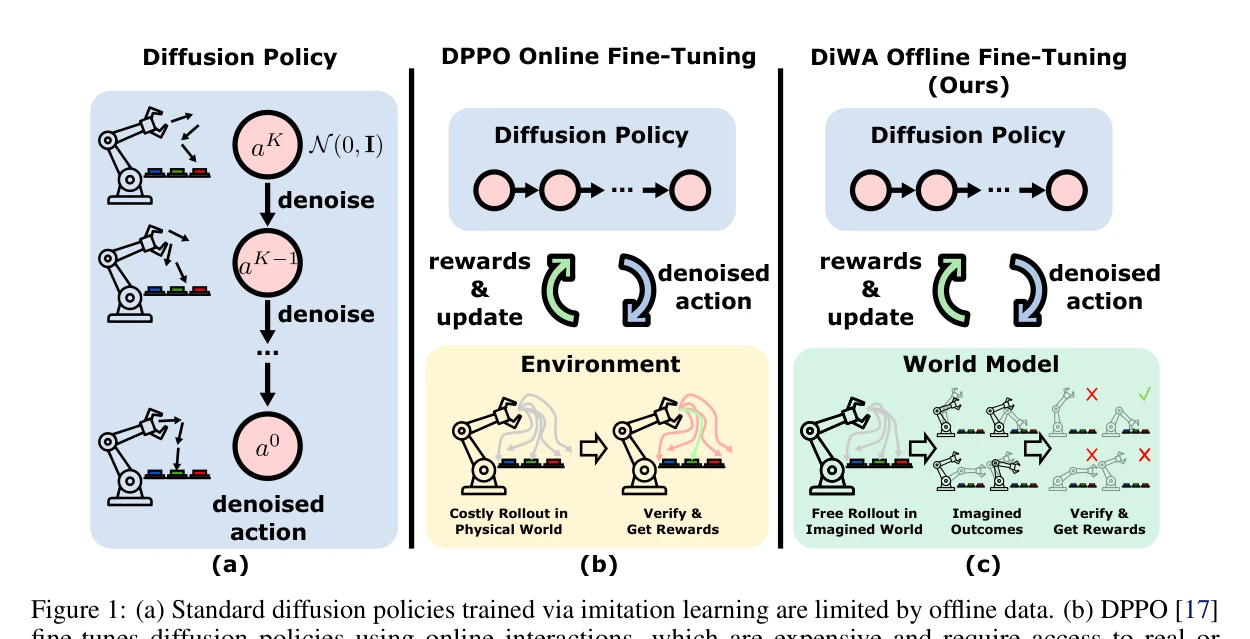
Figure 1: (a) Standard diffusion policies trained via imitation learning are limited by offline data. (b) DPPO [17]
DiWA는 학습된 world model을 활용하여 diffusion 기반 로봇 정책을 오프라인으로 미세조정하는 프레임워크로, RL을 통해 상상 속 롤아웃에서 정책을 개선한다.
저자: Akshay L Chandra, Iman Nematollahi, Chenguang Huang, Tim Welschehold, Wolfram Burgard, Abhinav Valada | 날짜: 2025-08-05 | URL: https://arxiv.org/abs/2508.03645 📄 PDF
Figure 1: (a) Standard diffusion policies trained via imitation learning are limited by offline data. (b) DPPO [17]
DiWA는 학습된 world model을 활용하여 diffusion 기반 로봇 정책을 오프라인으로 미세조정하는 프레임워크로, RL을 통해 상상 속 롤아웃에서 정책을 개선한다.
Figure 1: (a) Standard diffusion policies trained via imitation learning are limited by offline data. (b) DPPO [17]
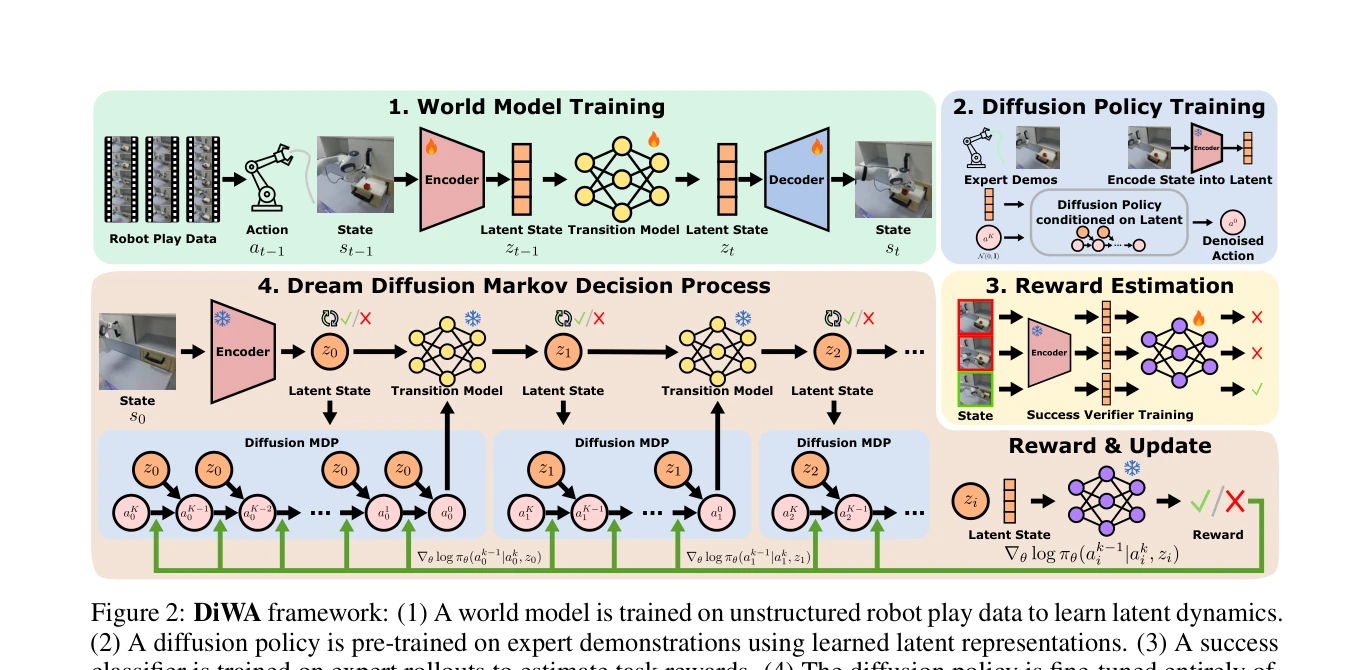
Figure 2: DiWA framework: (1) A world model is trained on unstructured robot play data to learn latent dynamics.
총평: DiWA는 world model을 활용한 offlineRL로 diffusion policy 미세조정의 샘플 효율성을 획기적으로 개선한 혁신적 연구로, 실제 로봇 학습의 실무적 도전 과제를 해결하는 의미 있는 기여이다.