Essence
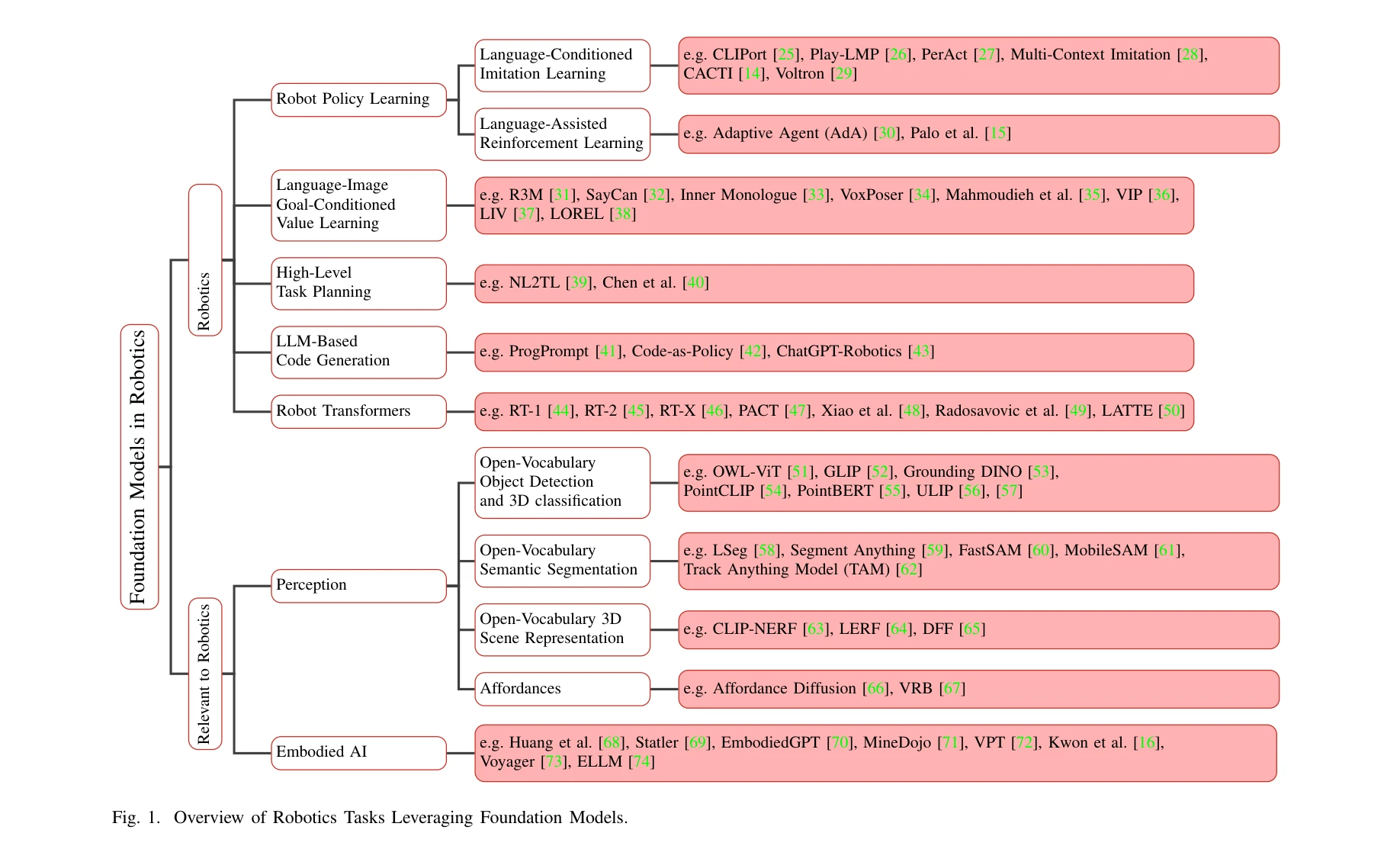
Fig. 1. Overview of Robotics Tasks Leveraging Foundation Models.
본 논문은 로봇 자동화 스택의 지각, 의사결정, 제어 전반에 걸쳐 foundation model의 응용을 포괄적으로 조사하며, 로봇 도메인 적용 시 데이터 부족, 실시간 성능, 안전성 보장 등의 주요 과제를 제시한다.
저자: Roya Firoozi, Johnathan Tucker, Stephen Tian, Anirudha Majumdar, Jiankai Sun, Weiyu Liu, Yuke Zhu, Shuran Song, Ashish Kapoor, Karol Hausman, Brian Ichter, Danny Driess, Jiajun Wu, Cewu Lu, Mac Schwager | 날짜: 2023-12-13 | URL: https://arxiv.org/abs/2312.07843 📄 PDF
Fig. 1. Overview of Robotics Tasks Leveraging Foundation Models.
본 논문은 로봇 자동화 스택의 지각, 의사결정, 제어 전반에 걸쳐 foundation model의 응용을 포괄적으로 조사하며, 로봇 도메인 적용 시 데이터 부족, 실시간 성능, 안전성 보장 등의 주요 과제를 제시한다.
Fig. 1. Overview of Robotics Tasks Leveraging Foundation Models.
총평: 본 논문은 로봇 자동화에서 foundation model의 역할을 체계적으로 정리한 중요한 조사 논문으로, 기술적 성과뿐 아니라 안전성과 실시간 성능이라는 실무적 과제를 균형있게 다루어 해당 분야의 나침반 역할을 할 수 있다.