Essence

Figure 1: LLMs have some internal knowledge about robot motions, but cannot directly translate them into actions
LLM을 이용하여 자연어 명령을 보상 함수로 변환하고, 실시간 최적화기(MuJoCo MPC)로 로봇 행동을 합성하는 새로운 패러다임을 제시한다.
저자: Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, Yuval Tassa, Fei Xia | 날짜: 2023-06-14 | URL: https://arxiv.org/abs/2306.08647 📄 PDF
Figure 1: LLMs have some internal knowledge about robot motions, but cannot directly translate them into actions
LLM을 이용하여 자연어 명령을 보상 함수로 변환하고, 실시간 최적화기(MuJoCo MPC)로 로봇 행동을 합성하는 새로운 패러다임을 제시한다.
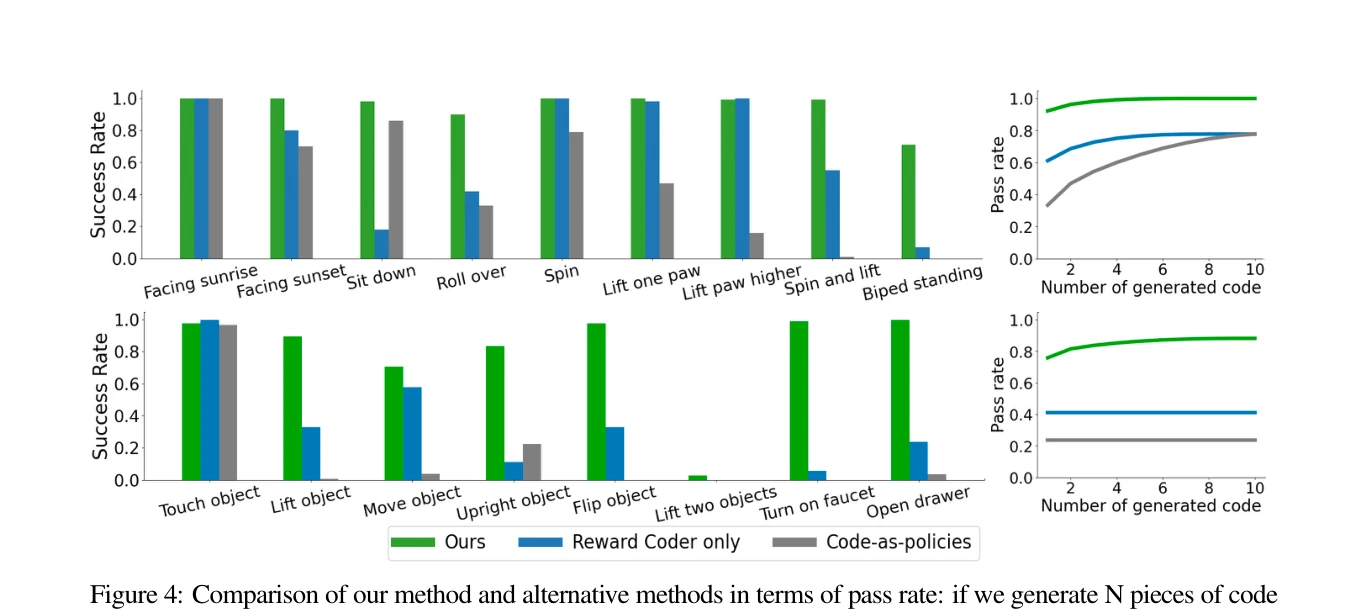
Figure 4: Comparison of our method and alternative methods in terms of pass rate: if we generate N pieces of code
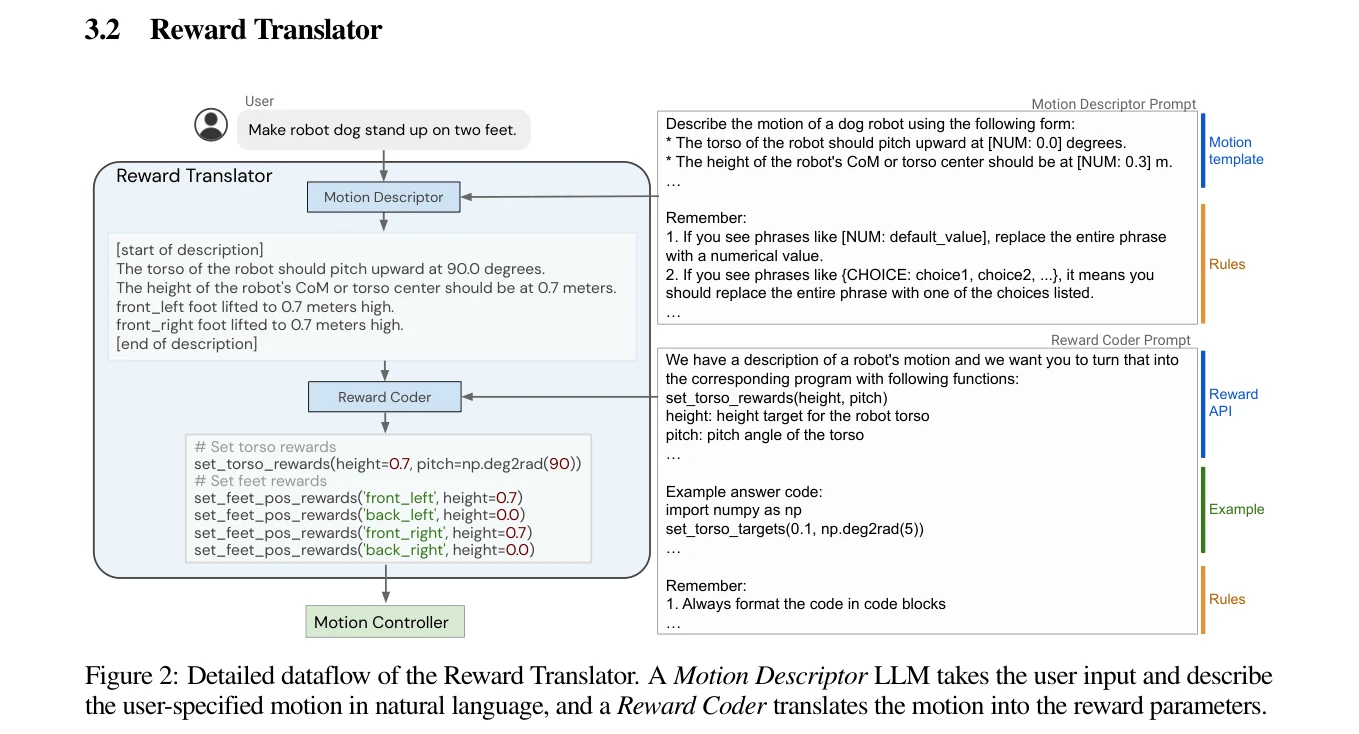
Figure 2: Detailed dataflow of the Reward Translator. A Motion Descriptor LLM takes the user input and describe
총평: 이 논문은 LLM을 보상 함수 생성기로 활용하여 자연언어와 저수준 로봇 동작 사이의 간극을 효과적으로 해소하는 혁신적인 접근법을 제시한다. 강력한 실험 결과와 실제 로봇 검증을 통해 방법론의 타당성을 입증하며, 로봇 제어에서 LLM 활용의 새로운 방향을 제시한다.