Essence

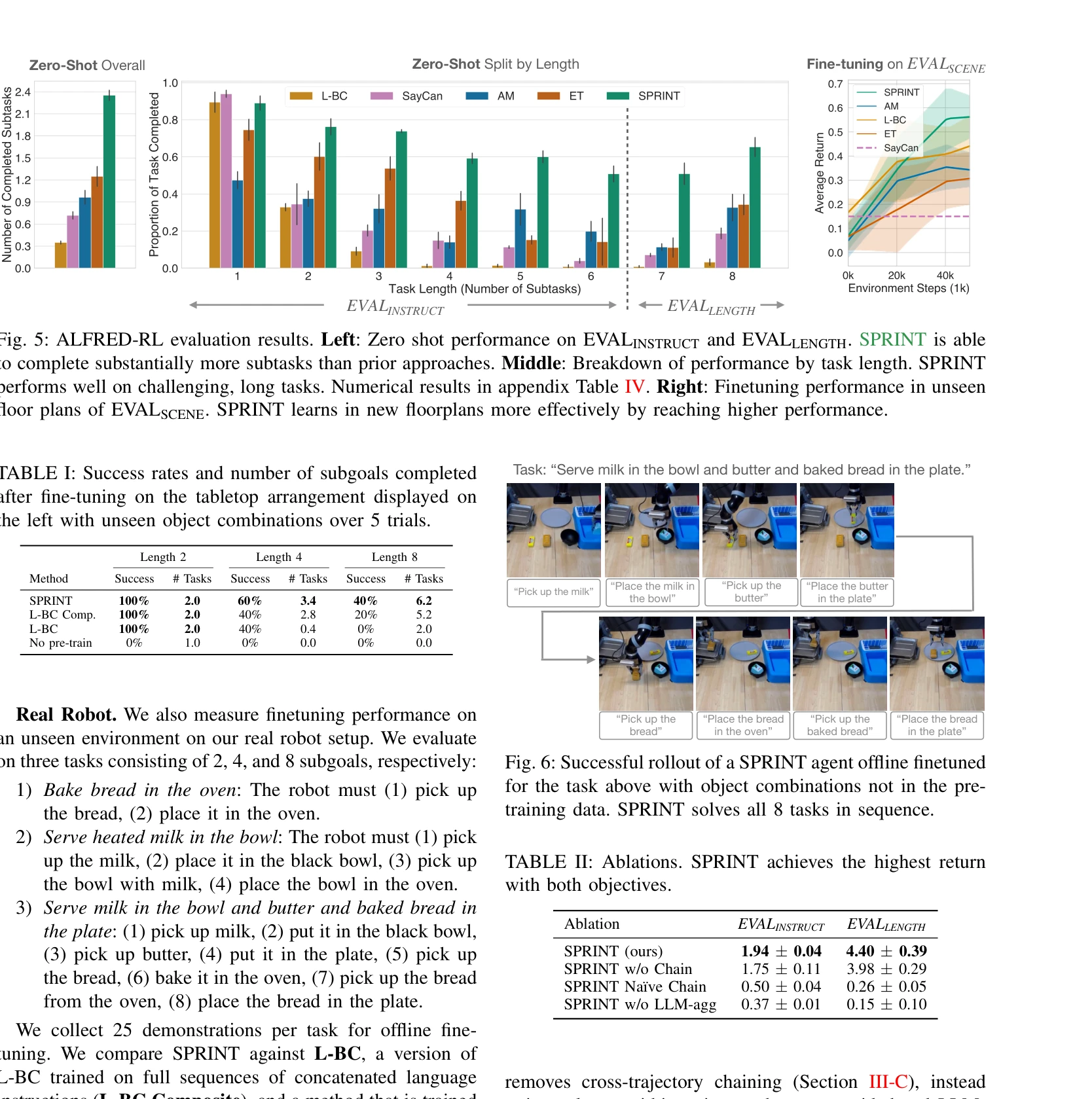
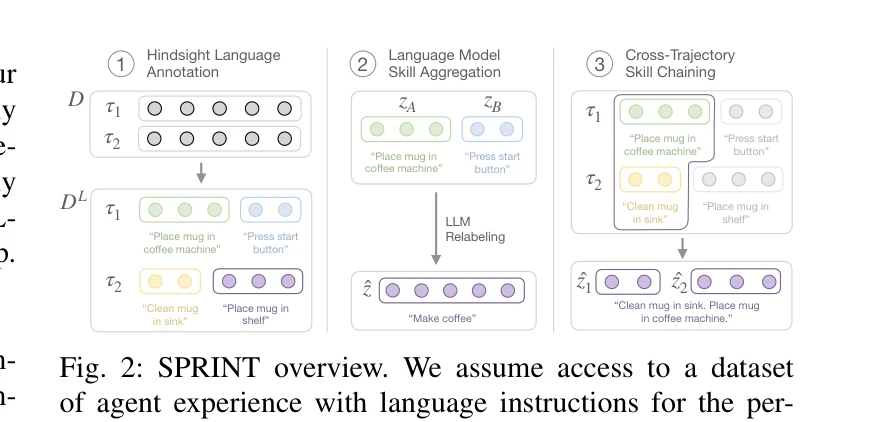
Fig. 1: SPRINT is a scalable approach for pre-training robot policies with a rich repertoire of skills while minimizing
SPRINT는 대규모 언어 모델(LLM)을 활용한 instruction relabeling과 offline RL 기반 cross-trajectory skill chaining을 통해 로봇 정책 사전학습을 위한 인간 주석 비용을 크게 줄이는 확장 가능한 접근법이다.