Essence
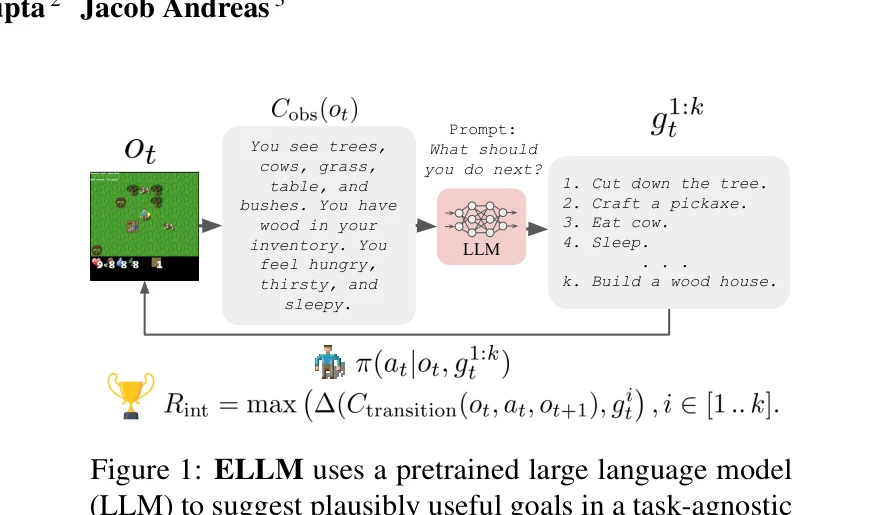
Figure 1: ELLM uses a pretrained large language model
ELLM은 대규모 언어모델(LLM)을 활용하여 RL 에이전트의 탐색을 인간의 상식적 지식으로 안내하는 방법을 제안한다. 현재 상태에 기반해 LLM이 제시하는 목표 달성을 보상함으로써 의미 있는 행동 학습을 유도한다.
저자: Yuqing Du, Olivia Watkins, Zihan Wang, Cédric Colas, Trevor Darrell, Pieter Abbeel, Abhishek Gupta, Jacob Andreas | 날짜: 2023-02-13 | URL: https://arxiv.org/abs/2302.06692 📄 PDF
Figure 1: ELLM uses a pretrained large language model
ELLM은 대규모 언어모델(LLM)을 활용하여 RL 에이전트의 탐색을 인간의 상식적 지식으로 안내하는 방법을 제안한다. 현재 상태에 기반해 LLM이 제시하는 목표 달성을 보상함으로써 의미 있는 행동 학습을 유도한다.
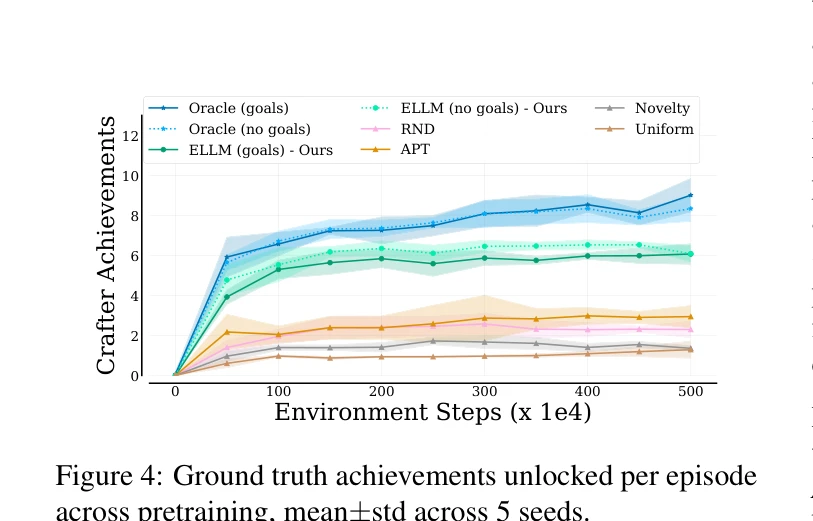
Figure 4: Ground truth achievements unlocked per episode
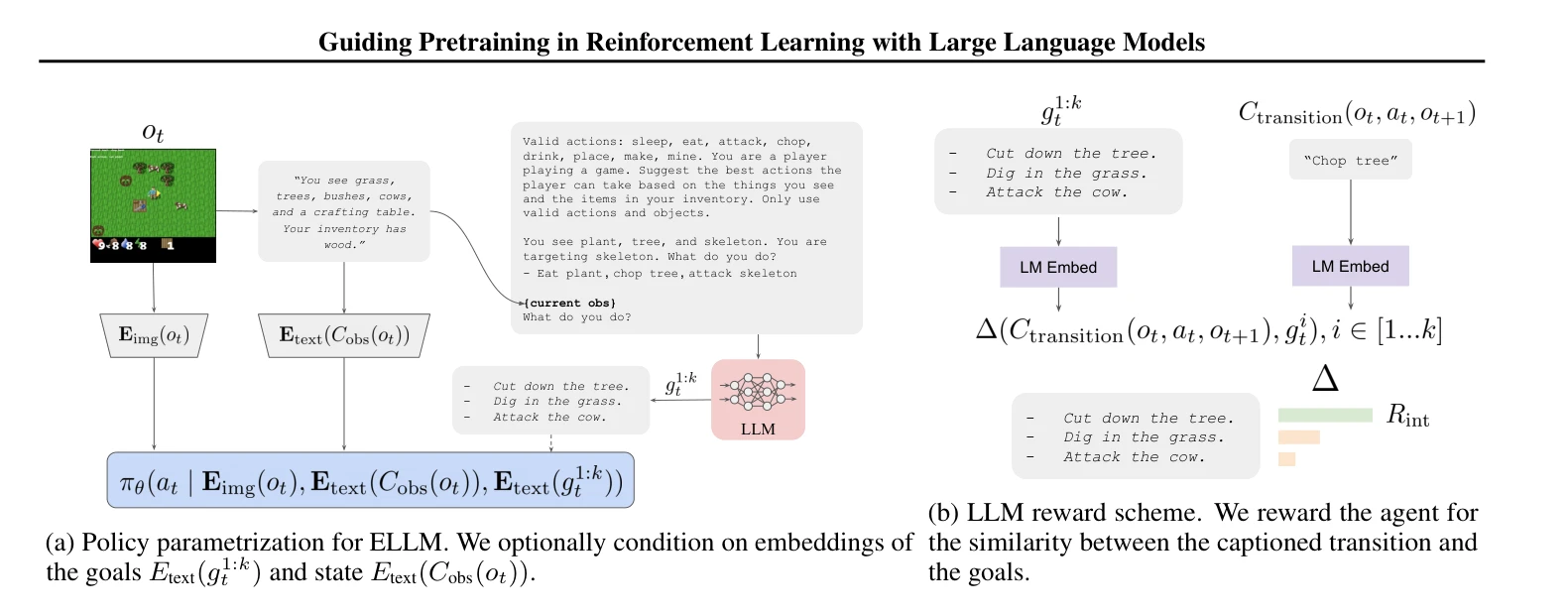
Figure 2: ELLM uses GPT-3 to suggest adequate exploratory goals and SentenceBERT embeddings to compute the similarity
총평: ELLM은 내재적 동기 탐색의 근본적 문제인 '무관한 신규성 추구'를 대규모 언어모델의 상식 지식으로 창의적으로 해결한 연구이다. 실험 결과가 제한적이고 계산 비용 이슈가 있지만, LLM을 RL 탐색에 통합하는 novel한 접근과 실질적 성능 향상은 이 분야에 중요한 기여를 한다.