저자: Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, Tao Yu | 날짜: 2023-09-20 | URL: https://arxiv.org/abs/2309.11489 📄 PDF
Essence
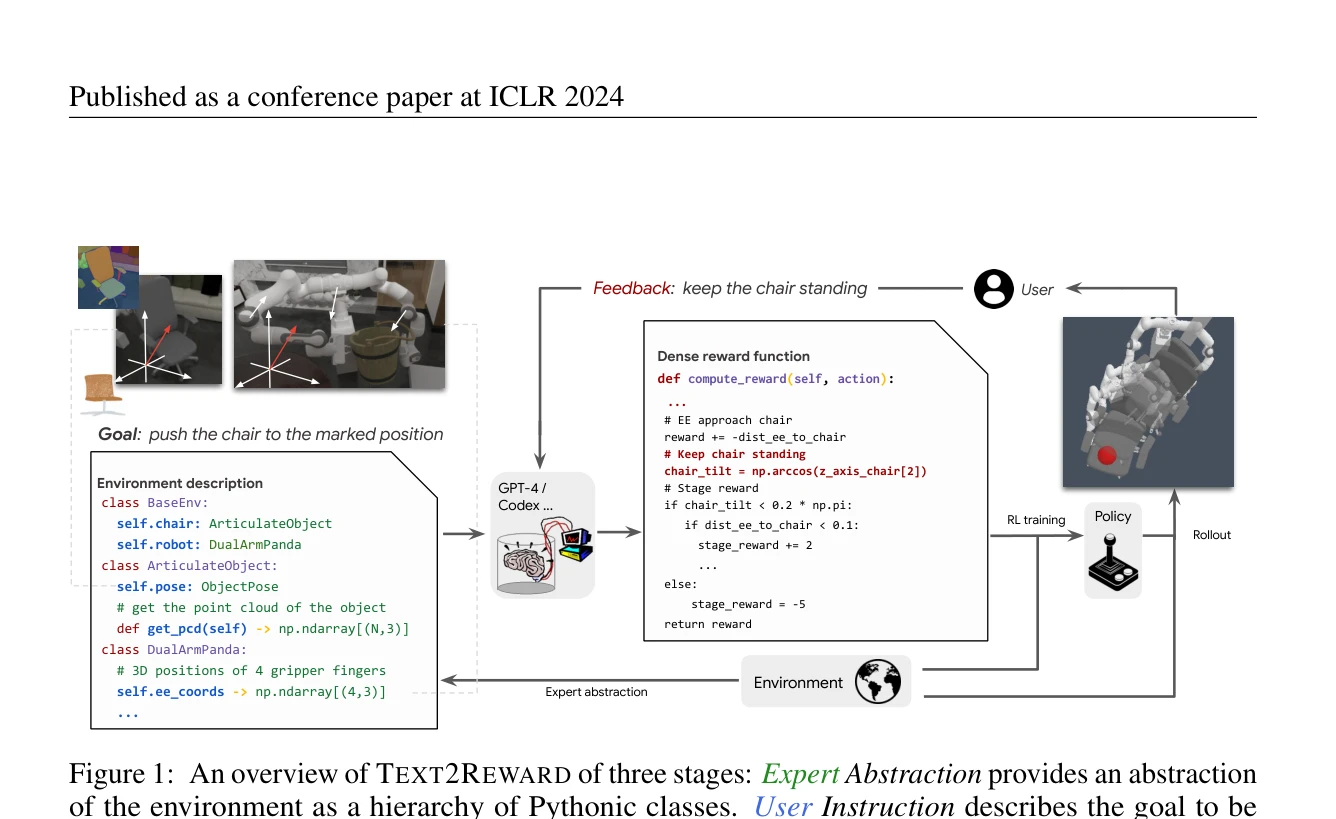
Figure 1: An overview of TEXT2REWARD of three stages: Expert Abstraction provides an abstraction
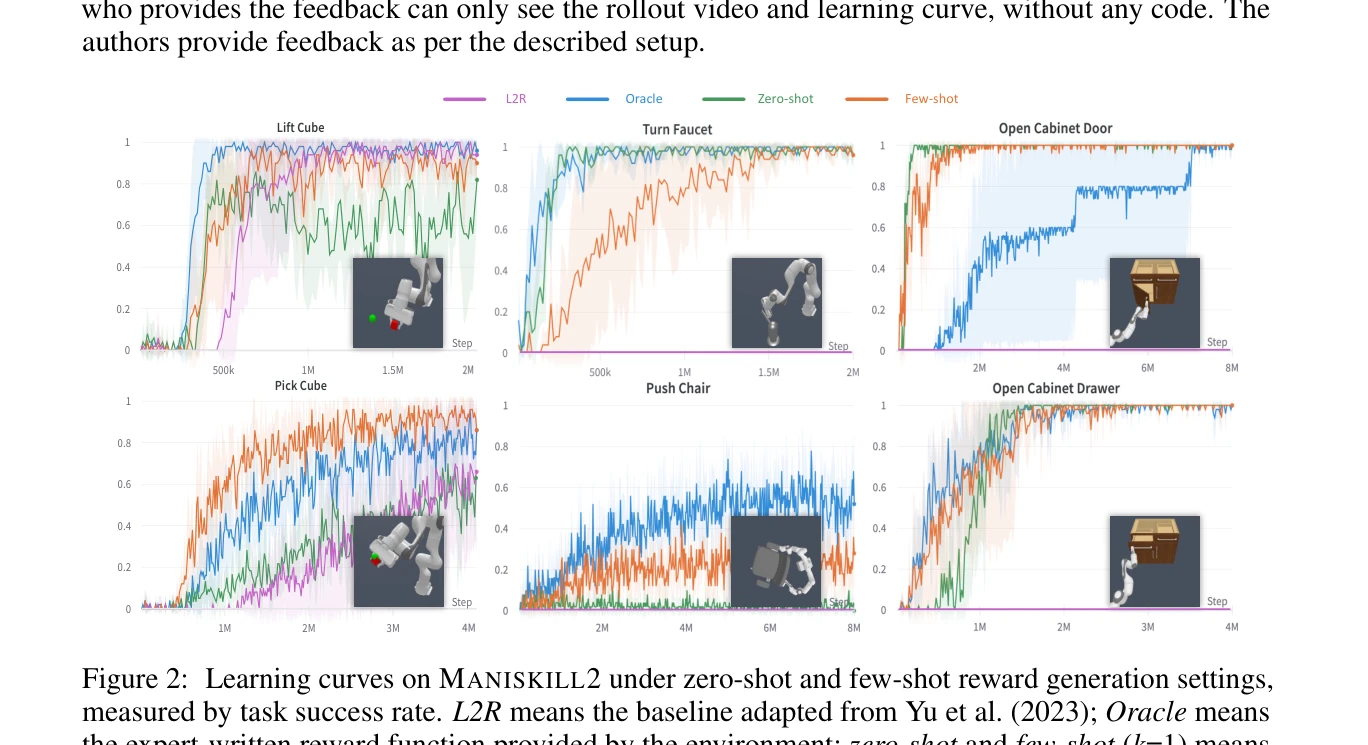
LLM을 활용하여 자연어로 기술된 목표로부터 자동으로 dense reward function을 생성하고 형성하는 data-free 프레임워크 Text2Reward를 제시한다. 생성된 reward code는 해석 가능하고 실행 가능한 프로그램 형태로, 기존의 inverse RL이나 sparse reward 기반 방법들보다 넓은 범위의 작업을 지원한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM 기반 reward code 자동 생성으로 RL의 오랜 challenge인 reward design을 혁신적으로 해결하며, Pythonic 추상화와 code execution feedback을 통해 높은 해석성과 신뢰성을 달성했다. 광범위한 로봇 벤치마크와 실제 로봇 배포로 실용성을 입증하고 human-in-the-loop 파이프라인으로 실무 적용 가능성을 보여주는 ICLR 2024의 우수 논문이다.