저자: Linqing Zhong, Chen Gao, Zihan Ding, Yue Liao, Huimin Ma, Shifeng Zhang, Xu Zhou, Si Liu | 날짜: 2024-11-25 | URL: https://arxiv.org/abs/2411.16425 📄 PDF
Essence
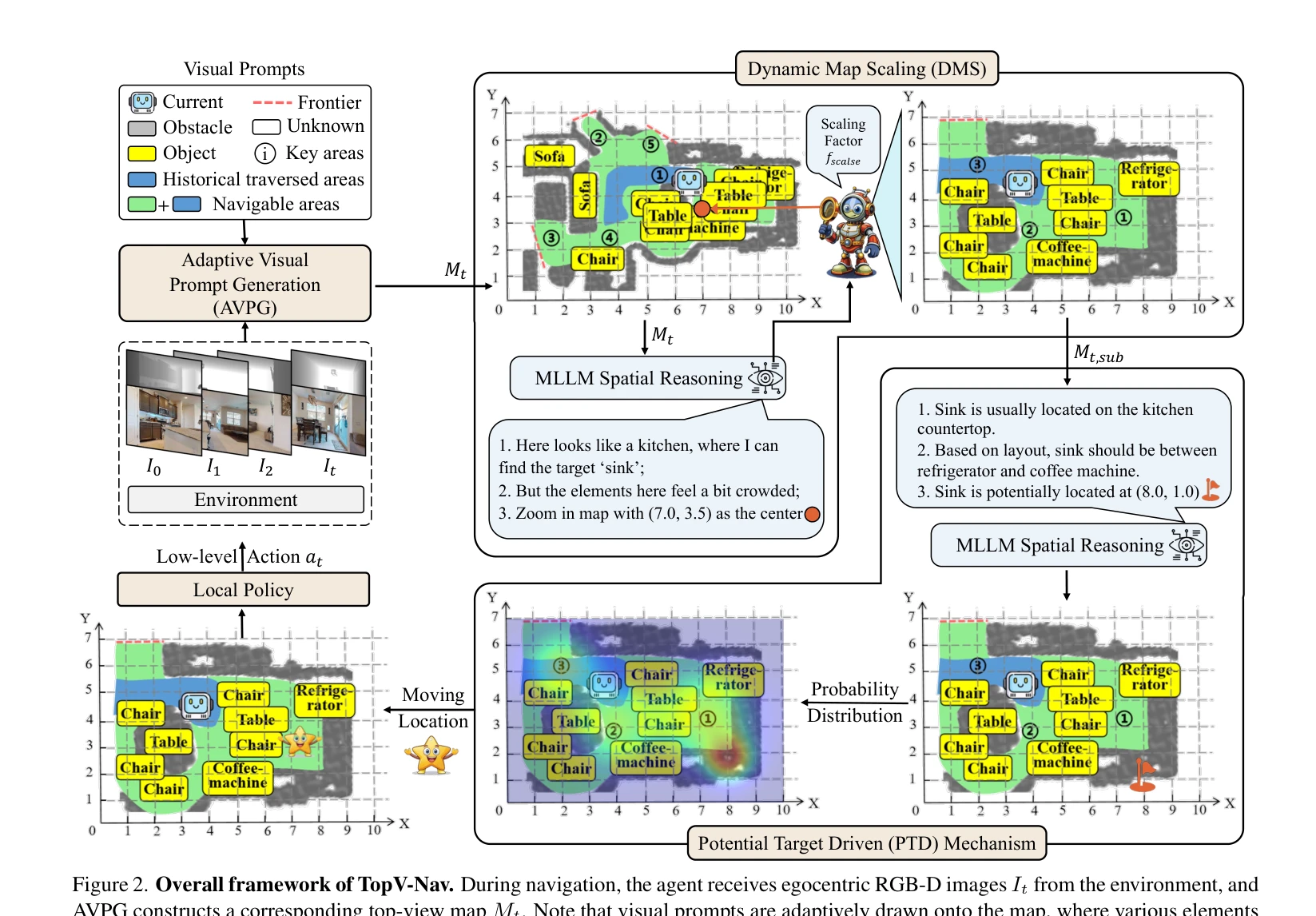
Figure 2. Overall framework of TopV-Nav. During navigation, the agent receives egocentric RGB-D images It from the envir
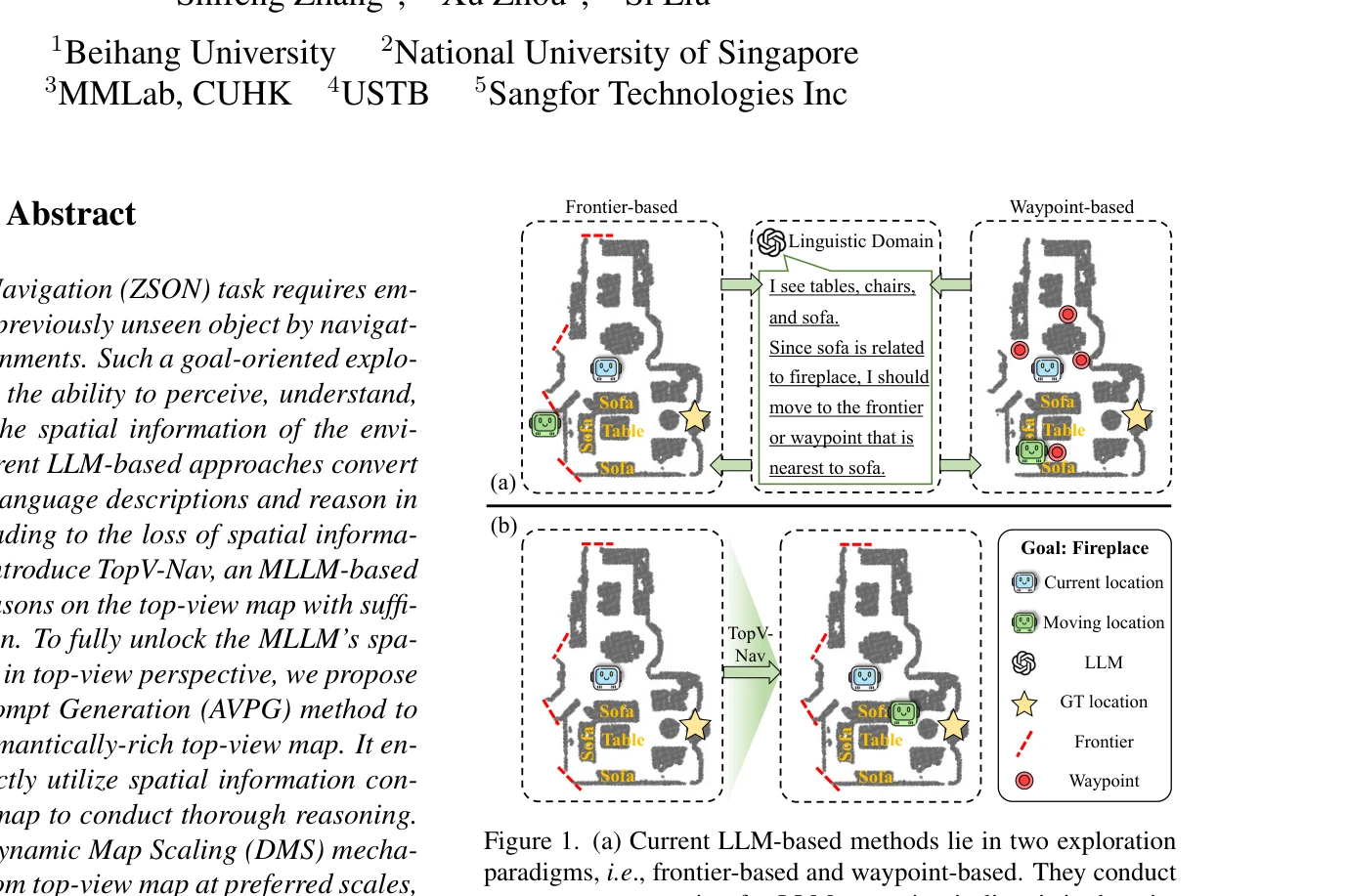
TopV-Nav는 MLLM을 활용하여 top-view 지도 위에서 직접 공간 추론을 수행함으로써 Zero-Shot Object Navigation 작업을 개선하는 방법론이다. Adaptive Visual Prompt Generation, Dynamic Map Scaling, Potential Target Driven 메커니즘을 통해 공간 정보 손실을 방지하고 의미론적 탐색 공간을 확대한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: TopV-Nav는 MLLM의 공간 추론 능력을 체계적으로 활용하여 ZSON 작업의 근본적인 한계를 해결하는 창의적이고 실질적인 방법론이다. Map-to-text 제거와 적응적 시각 프롬프트 생성 등 여러 혁신 기법이 효과적으로 통합되었으며, MP3D와 HM3D에서 우수한 성능을 달성했다.