Essence
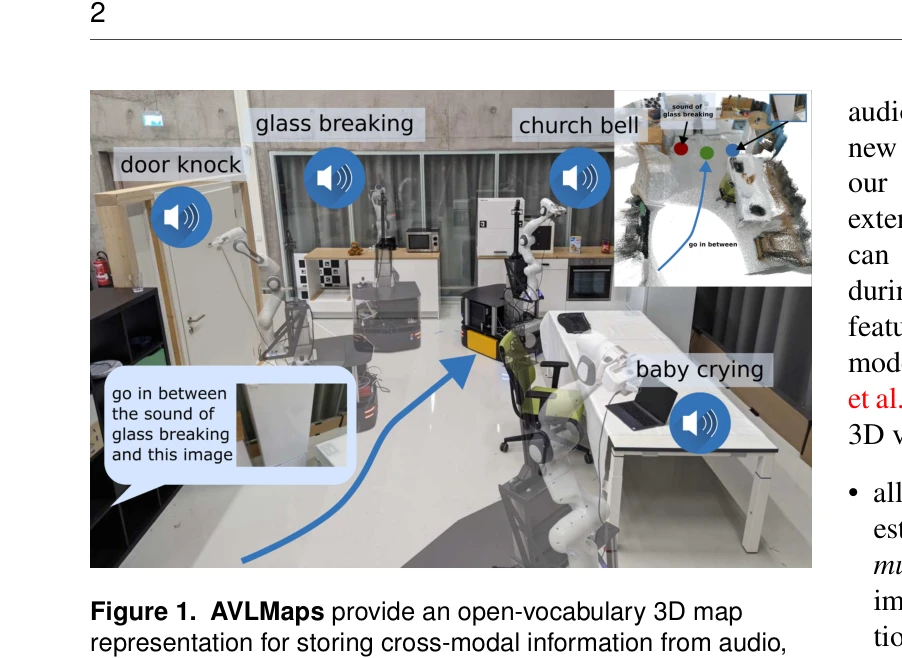
Figure 1. AVLMaps provide an open-vocabulary 3D map
로봇 네비게이션과 조작을 위해 pretrained multimodal foundation model의 특징을 3D 환경 재구성과 융합한 spatial language map (VLMaps, AVLMaps)을 제안한다. 이를 통해 자연어, 이미지, 오디오 등 다중모달 쿼리를 공간상의 목표 위치로 그라운딩할 수 있다.
저자: Chenguang Huang, Oier Mees, Andy Zeng, Wolfram Burgard | 날짜: 2025-06-07 | URL: https://arxiv.org/abs/2506.06862 📄 PDF
Figure 1. AVLMaps provide an open-vocabulary 3D map
로봇 네비게이션과 조작을 위해 pretrained multimodal foundation model의 특징을 3D 환경 재구성과 융합한 spatial language map (VLMaps, AVLMaps)을 제안한다. 이를 통해 자연어, 이미지, 오디오 등 다중모달 쿼리를 공간상의 목표 위치로 그라운딩할 수 있다.
Figure 1. AVLMaps provide an open-vocabulary 3D map
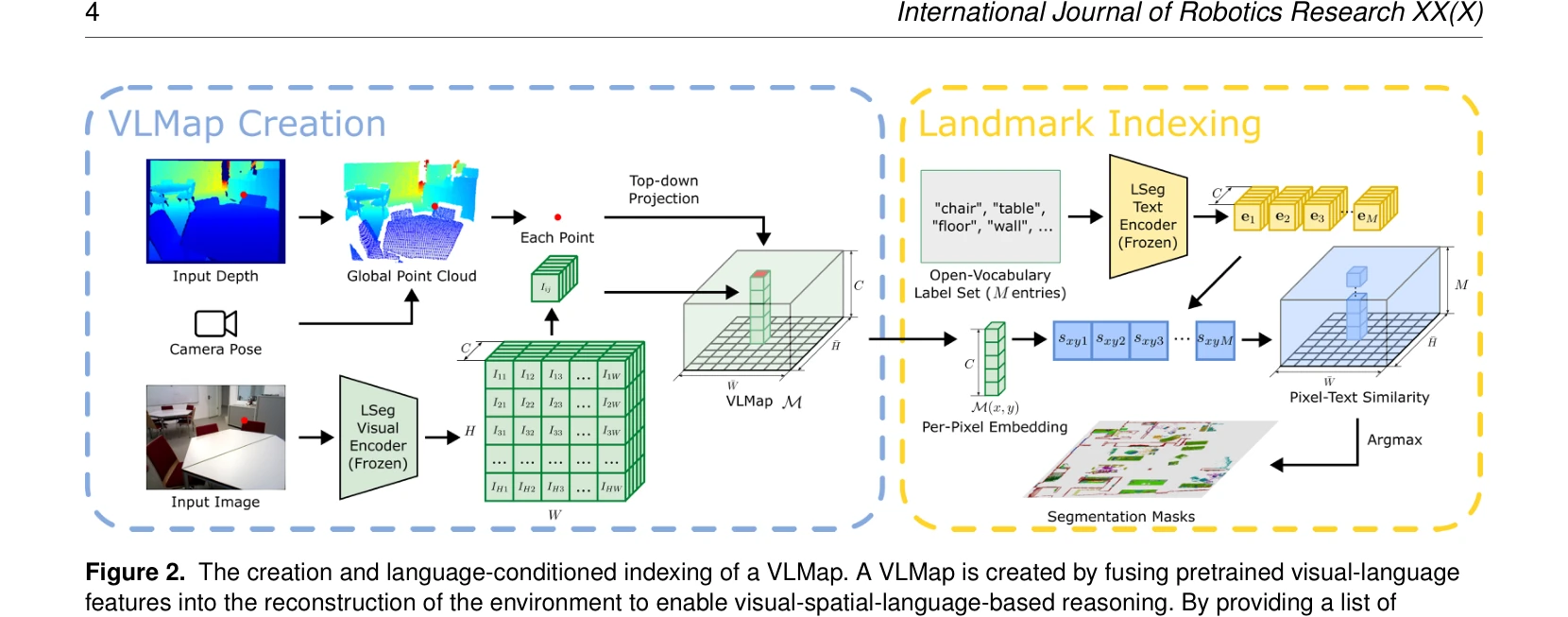
Figure 2. The creation and language-conditioned indexing of a VLMap. A VLMap is created by fusing pretrained visual-lang
총평: 본 논문은 multimodal foundation models을 3D spatial map에 창의적으로 통합하여 기존 방법의 공간 정밀도와 멀티모달 이해 한계를 동시에 해결한 의미 있는 기여다. Audio modality의 도입과 다양한 로봇 플랫폼 지원으로 실용적 확장성이 우수하며, 50% 성능 향상 등 정량적 결과도 강력하다.