저자: Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang | 날짜: 2024-02-24 | URL: https://arxiv.org/abs/2402.15852 📄 PDF
Essence
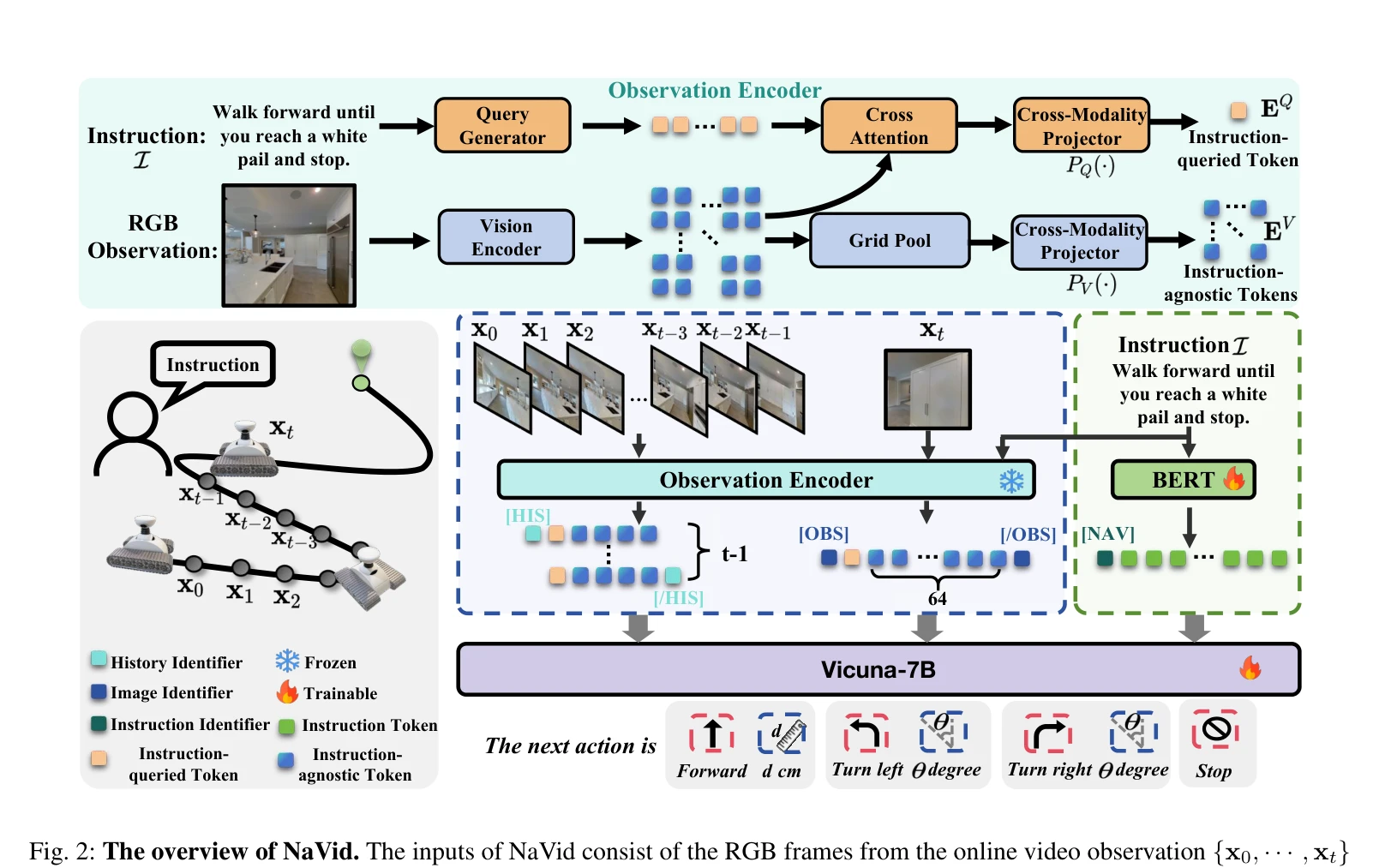
Fig. 2: The overview of NaVid. The inputs of NaVid consist of the RGB frames from the online video observation {x0, · ·
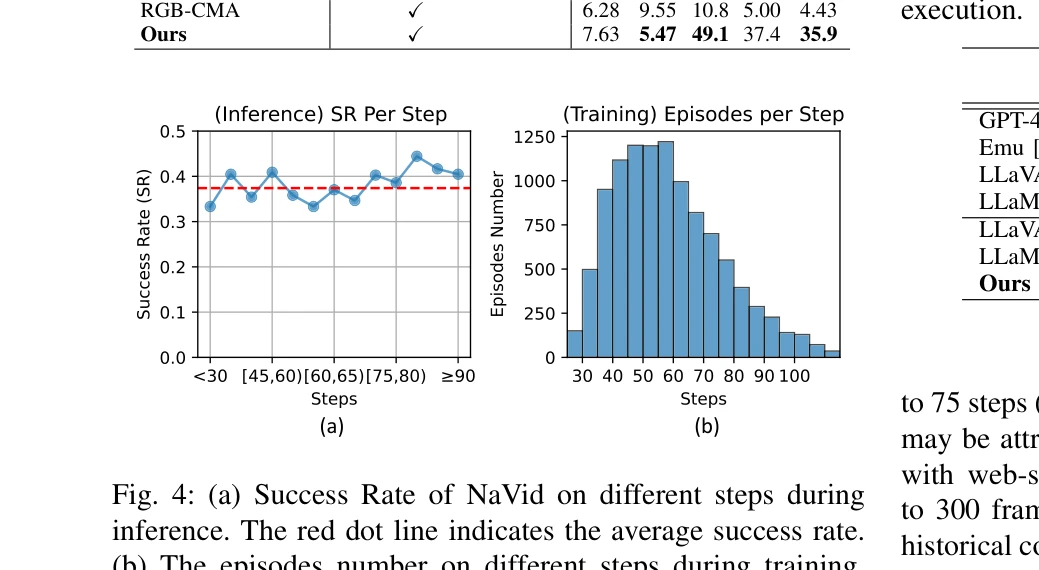
NaVid는 비디오 기반 대규모 VLM을 활용하여 시각-언어 네비게이션에서 RGB 카메라 입력만으로 로봇의 다음 행동을 계획하는 첫 시도이며, 지도나 깊이 정보 없이 시뮬레이션과 실제 환경 모두에서 최고 성능을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: NaVid는 VLM의 강력한 일반화 능력을 VLN에 성공적으로 적용한 혁신적 연구로, RGB만으로 연속 환경에서 실제 로봇 네비게이션을 수행하는 첫 실용적 VLA 모델이다. Sim-to-Real 전이의 오랜 문제를 우아하게 해결하고 우수한 크로스 데이터셋 일반화를 보여준다.