저자: An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, Xiaolong Wang | 날짜: 2024-12-05 | URL: https://arxiv.org/abs/2412.04453 📄 PDF
Essence
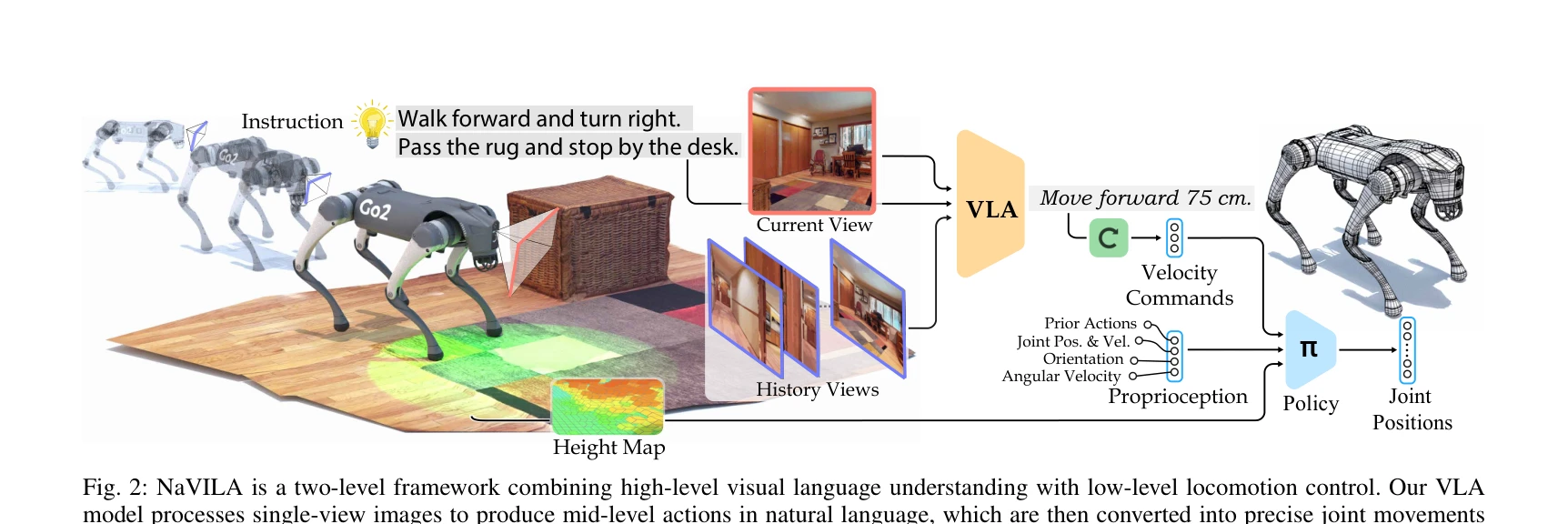
Fig. 2: NaVILA is a two-level framework combining high-level visual language understanding with low-level locomotion con
NaVILA는 Vision-Language-Action 모델과 locomotion RL policy를 통합한 2-단계 프레임워크로, 인간 언어 명령을 legged 로봇의 저수준 관절 제어로 번역하여 복잡한 환경에서의 시각-언어 네비게이션을 실현한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: NaVILA는 언어 기반 고수준 추론과 저수준 로봇 제어를 효과적으로 분리하는 혁신적 프레임워크로, 광범위한 벤치마크 개선, 실세계 검증, 로봇 간 일반화 능력을 통해 legged 로봇 내비게이션의 실질적 진전을 이룬 우수한 연구이다.
