저자: Isabel Leal, Krzysztof Choromanski, Deepali Jain, Avinava Dubey, Jake Varley, Michael Ryoo, Yao Lu, Frederick Liu, Vikas Sindhwani, Quan Vuong, Tamas Sarlos, Ken Oslund, Karol Hausman, Kanishka Rao | 날짜: 2023-12-04 | URL: https://arxiv.org/abs/2312.01990 📄 PDF
Essence

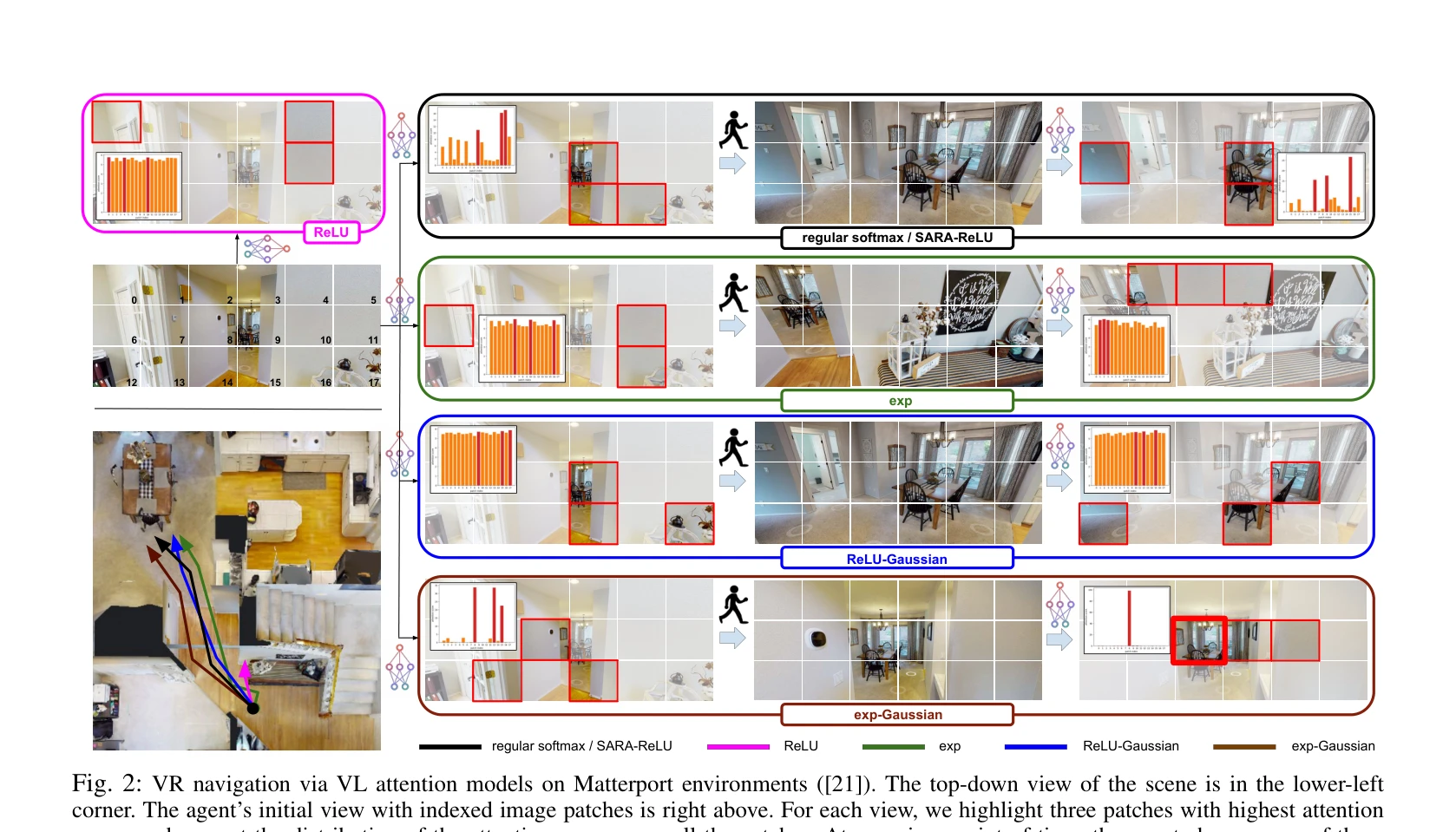
Fig. 1: Robotics Transformer policies obtained via Self-Adaptive Robust Attention (SARA) in action for three different m
SARA-RT는 Robotics Transformer를 on-robot 배포에 적합하도록 선형 주의(linear attention)로 변환하는 up-training 방법을 제시하여, quadratic 복잡도의 모델을 high quality 유지하면서 효율화한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: SARA-RT는 Robotics Transformer의 on-robot 배포라는 중요한 실제 문제를 우아하고 효과적으로 해결하며, up-training과 Gaussian 전처리라는 간단하지만 혁신적인 방법을 제시한다. 다만, 구체적인 성능 벤치마크와 광범위한 평가가 보강되면 더욱 강력한 contribution이 될 것이다.