Essence
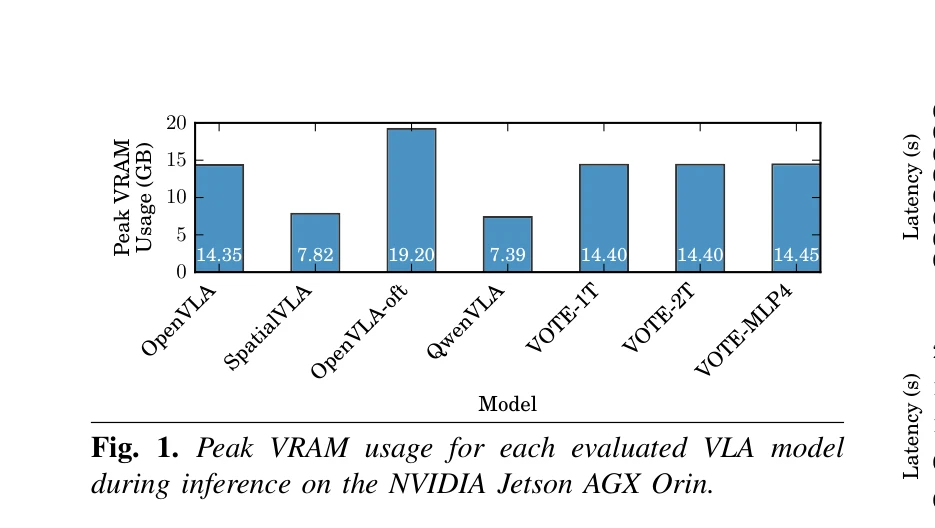
Fig. 1. Peak VRAM usage for each evaluated VLA model
Vision-Language-Action (VLA) 모델의 성능을 엣지 디바이스부터 데이터센터 GPU까지 다양한 하드웨어 플랫폼에서 체계적으로 평가하여, 아키텍처와 하드웨어 제약 조건에 따른 정확도, 레이턴시, 처리량, 메모리 사용량의 확장 추이를 밝혀낸다.
저자: Amir Taherin, Juyi Lin, Arash Akbari, Arman Akbari, Pu Zhao, Weiwei Chen, David Kaeli, Yanzhi Wang | 날짜: 2025-09-15 | URL: https://arxiv.org/abs/2509.11480 📄 PDF
Fig. 1. Peak VRAM usage for each evaluated VLA model
Vision-Language-Action (VLA) 모델의 성능을 엣지 디바이스부터 데이터센터 GPU까지 다양한 하드웨어 플랫폼에서 체계적으로 평가하여, 아키텍처와 하드웨어 제약 조건에 따른 정확도, 레이턴시, 처리량, 메모리 사용량의 확장 추이를 밝혀낸다.
Fig. 1. Peak VRAM usage for each evaluated VLA model
총평: 본 논문은 VLA 모델의 크로스 플랫폼 성능 확장을 체계적으로 분석한 중요한 벤치마크 연구로, 로봇 배포 시나리오에 맞는 하드웨어 선택과 모델 최적화를 위한 실용적인 통찰력을 제공한다. 엣지 디바이스의 경쟁력을 입증함으로써 로봇 시스템 설계에 대한 새로운 관점을 제시한다.