Essence
이 논문은 heterogeneous robot embodiments 및 tasks에 걸쳐 대규모 데이터로 사전학습하여 로봇 정책의 generalization 성능을 향상시키는 Heterogeneous Pre-trained Transformers (HPT)를 제안한다. 서로 다른 센서와 구동기를 가진 다양한 로봇 embodiments의 proprioception과 vision 정보를 shared latent space로 정렬하여 task-agnostic, embodiment-agnostic한 기초 모델을 학습한다.
Achievement
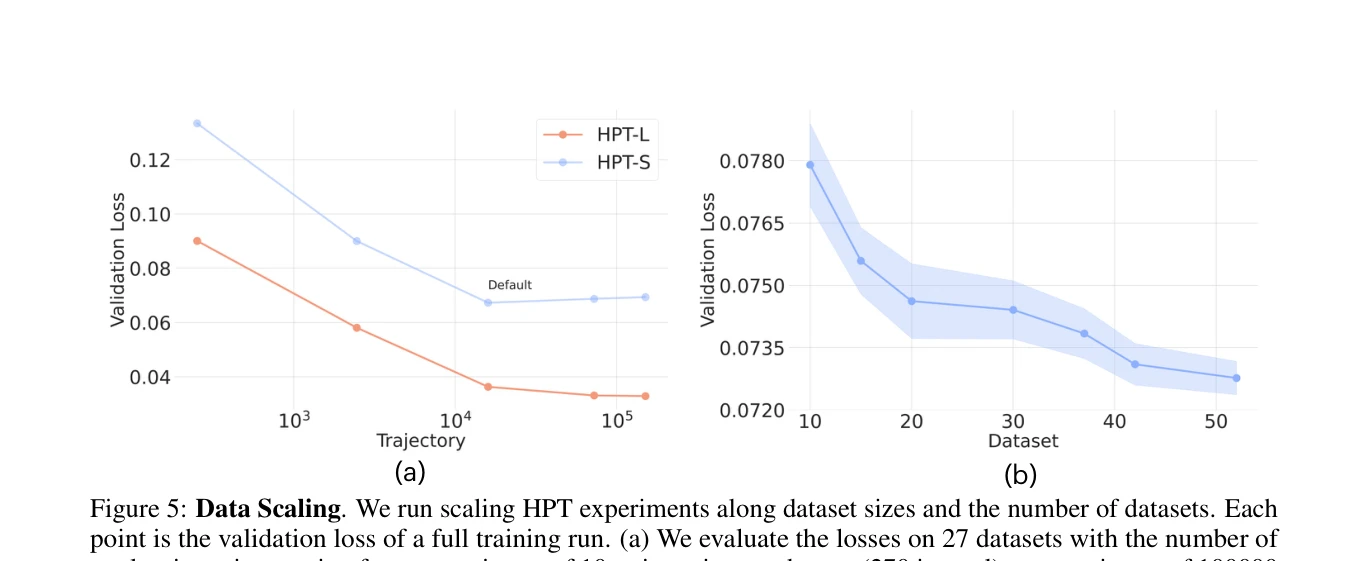
Figure 5: Data Scaling. We run scaling HPT experiments along dataset sizes and the number of datasets. Each
확장성 검증: 데이터셋 규모, 훈련 에포크, 모델 크기에 따른 scaling laws를 실증적으로 입증하여 로봇 정책 학습에서도 foundation models과 유사한 scaling 행동이 존재함을 보였다. 성능 향상: 여러 시뮬레이션 벤치마크(CALVIN, BRIDGE, Metaworld 등)와 실제 로봇 dexterous tasks에서 from-scratch baselines 대비 20% 이상의 성능 향상을 달성했다. 데이터 효율성: 사전학습된 표현이 새로운 embodiments로의 transfer 시 필요한 데이터량과 훈련 시간을 대폭 감소시킨다. 광범위한 데이터 통합: 실제 로봇 데이터, 시뮬레이션, 인간 비디오 등 이질적인 embodiment 도메인의 52개 datasets을 효과적으로 통합했다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 이 논문은 로봇 학습의 중요한 과제인 heterogeneous embodiments 간 knowledge transfer를 multimodal alignment와 대규모 사전학습으로 해결하는 실질적이고 체계적인 방법을 제시한다. 52개 datasets을 통한 광범위한 실험과 scaling laws의 입증은 로봇 도메인에서의 귀중한 기여이다. 다만 tokenizer 설계의 일반성, sim-to-real gap, 표현 공간에 대한 깊이 있는 분석 등에서 개선 여지가 있다.