저자: Chia-Yu Hung, Navonil Majumder, Haoyuan Deng, Liu Renhang, Yankang Ang, Amir Zadeh, Chuan Li, Dorien Herremans, Ziwei Wang, Soujanya Poria | 날짜: 2025-11-18 | URL: https://arxiv.org/abs/2511.14659 📄 PDF
Essence
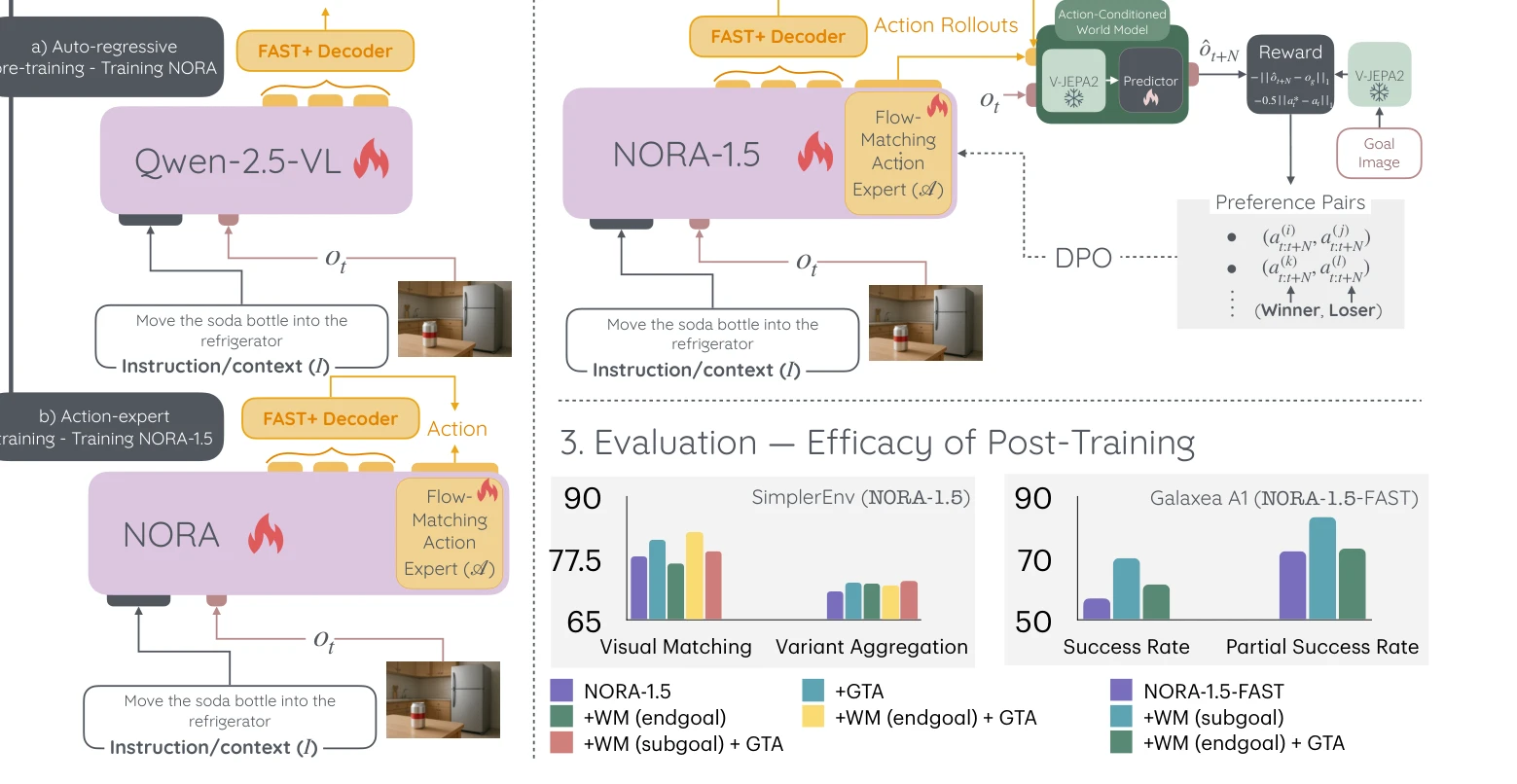
Figure 1. Training pipeline of NORA-1.5 where firstly a VLA model is pre-trained through imitation learning and subseque
NORA-1.5는 flow-matching 기반 action expert를 추가하여 VLA 모델의 성능을 향상시키고, world model 및 action-based reward를 이용한 DPO 기반 post-training으로 실제 로봇 환경에서의 신뢰성과 일반화 능력을 개선한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: NORA-1.5는 flow-matching 기반 아키텍처 개선과 경량이면서도 효과적인 reward 기반 post-training을 결합하여 VLA 모델의 신뢰성과 실제 배포 가능성을 크게 향상시킨 의미 있는 연구이다. 광범위한 벤치마크에서의 성과와 확장 가능한 post-training 방법론은 embodied AI 분야에 실질적인 기여를 한다.