저자: Enyu Zhao, Vedant Raval, Hejia Zhang, Jiageng Mao, Zeyu Shangguan, Stefanos Nikolaidis, Yue Wang, Daniel Seita | 날짜: 2025-05-14 | URL: https://arxiv.org/abs/2505.09698 📄 PDF
Essence
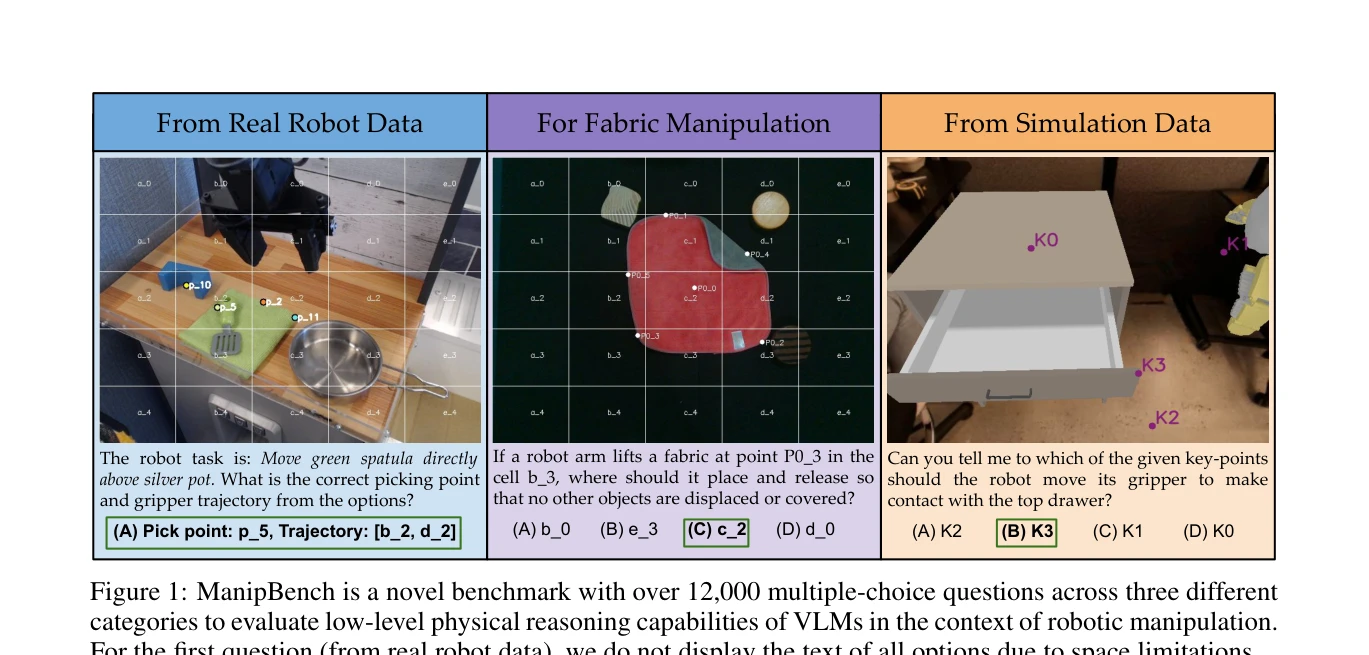
Figure 1: ManipBench is a novel benchmark with over 12,000 multiple-choice questions across three different
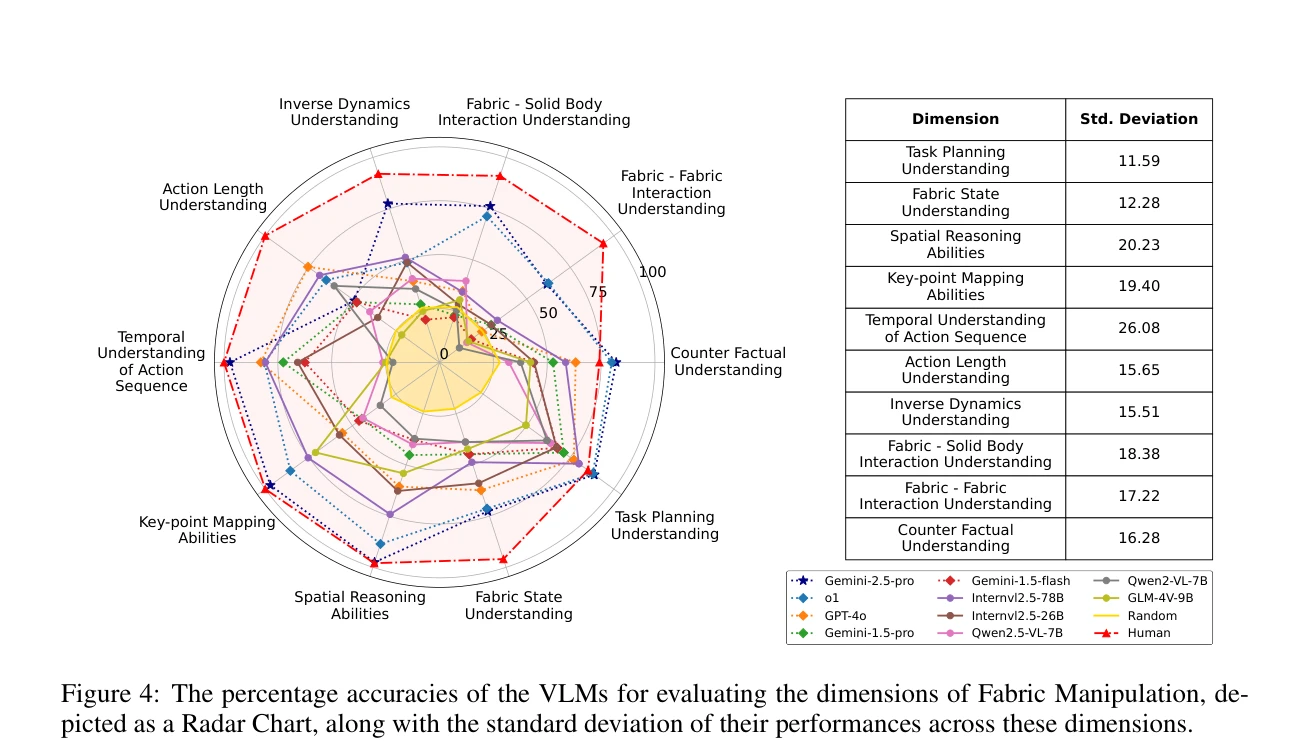
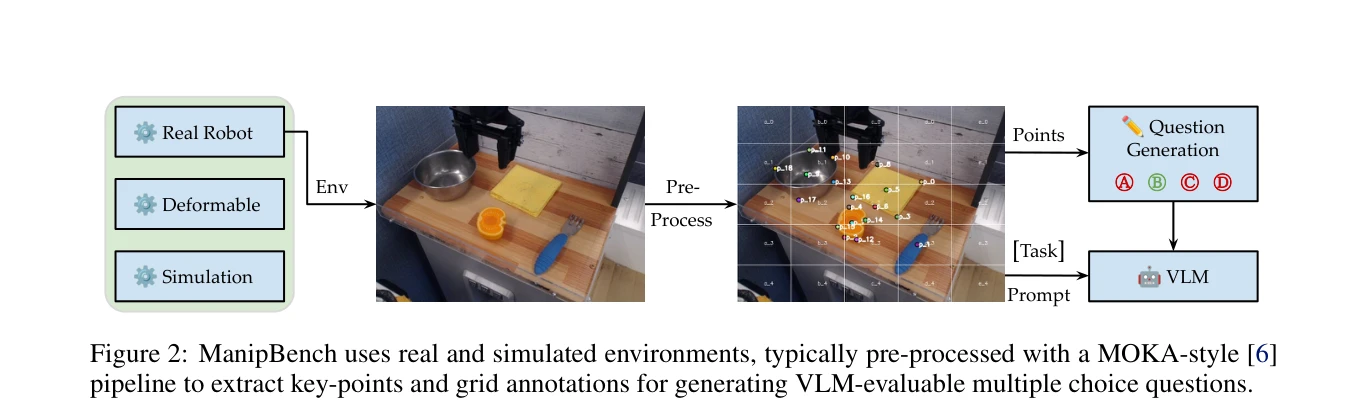
ManipBench는 Vision-Language Model(VLM)의 저수준 로봇 조작 추론 능력을 평가하기 위한 12,617개의 객관식 문제로 구성된 벤치마크이며, 33개의 VLM을 10개 모델 계열에서 광범위하게 테스트하여 성능 차이를 분석한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: ManipBench는 VLM의 저수준 로봇 조작 추론 능력을 체계적으로 평가하는 첫 종합 벤치마크로서, 광범위한 모델 평가, 포괄적 작업 범위, 현실 검증을 통해 로봇 조작 분야에 중요한 기여를 한다. 다만 평가 형식의 한계와 실제 로봇 검증의 확장 필요성이 있다.