Essence
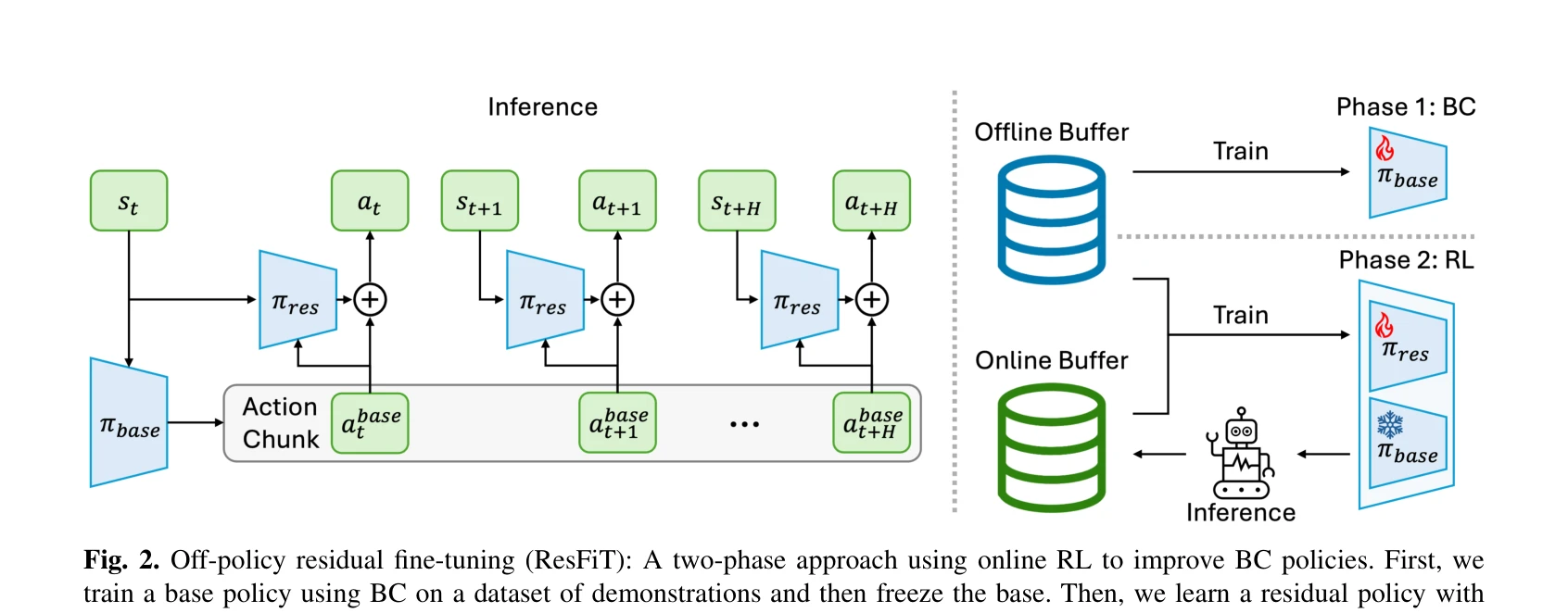
Fig. 2. Off-policy residual fine-tuning (ResFiT): A two-phase approach using online RL to improve BC policies. First, we
Behavior Cloning(BC) 정책을 기반으로 Residual Off-Policy RL을 적용하여 샘플 효율적으로 조작 정책을 개선하며, 고자유도 이족 로봇에서의 첫 실시간 RL 학습을 달성했다.
저자: Lars Ankile, Zhenyu Jiang, Rocky Duan, Guanya Shi, Pieter Abbeel, Anusha Nagabandi | 날짜: 2025-09-23 | URL: https://arxiv.org/abs/2509.19301 📄 PDF
Fig. 2. Off-policy residual fine-tuning (ResFiT): A two-phase approach using online RL to improve BC policies. First, we
Behavior Cloning(BC) 정책을 기반으로 Residual Off-Policy RL을 적용하여 샘플 효율적으로 조작 정책을 개선하며, 고자유도 이족 로봇에서의 첫 실시간 RL 학습을 달성했다.
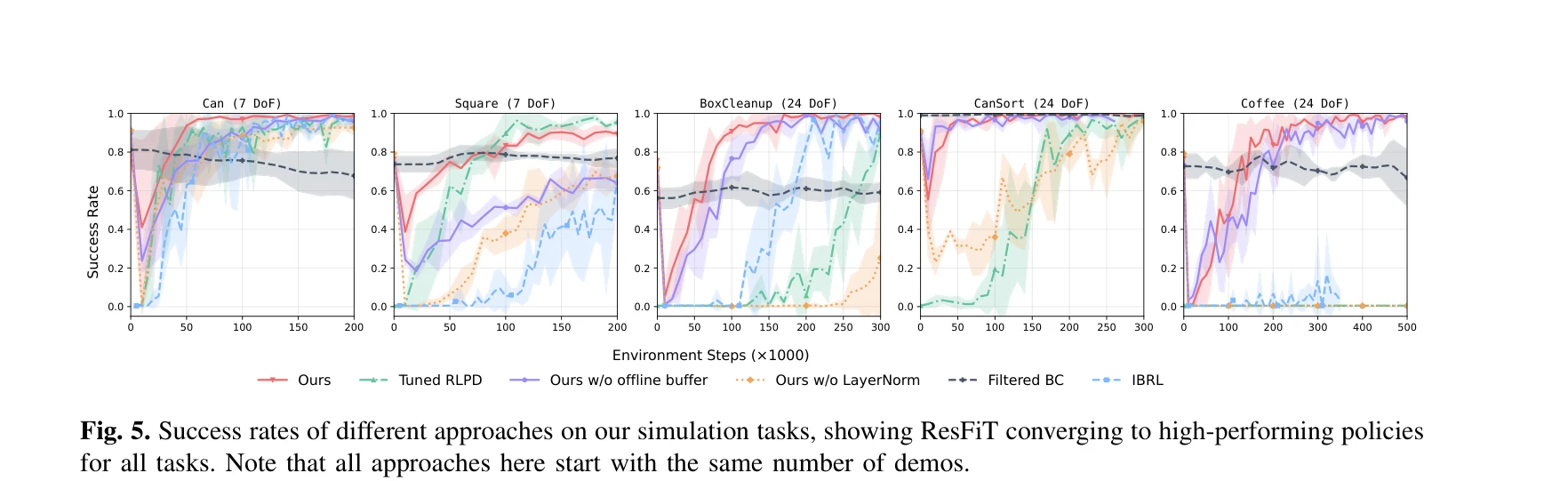
Fig. 5. Success rates of different approaches on our simulation tasks, showing ResFiT converging to high-performing poli
Fig. 2. Off-policy residual fine-tuning (ResFiT): A two-phase approach using online RL to improve BC policies. First, we
총평: BC와 off-policy RL을 residual learning으로 효과적으로 결합하여, 고자유도 실시간 로봇 학습의 실용적 경로를 제시했다. 블랙박스 방식의 일반성과 첫 휴머노이드 RL 실증이 로봇 학습 분야에 의미 있는 기여를 이룬다.