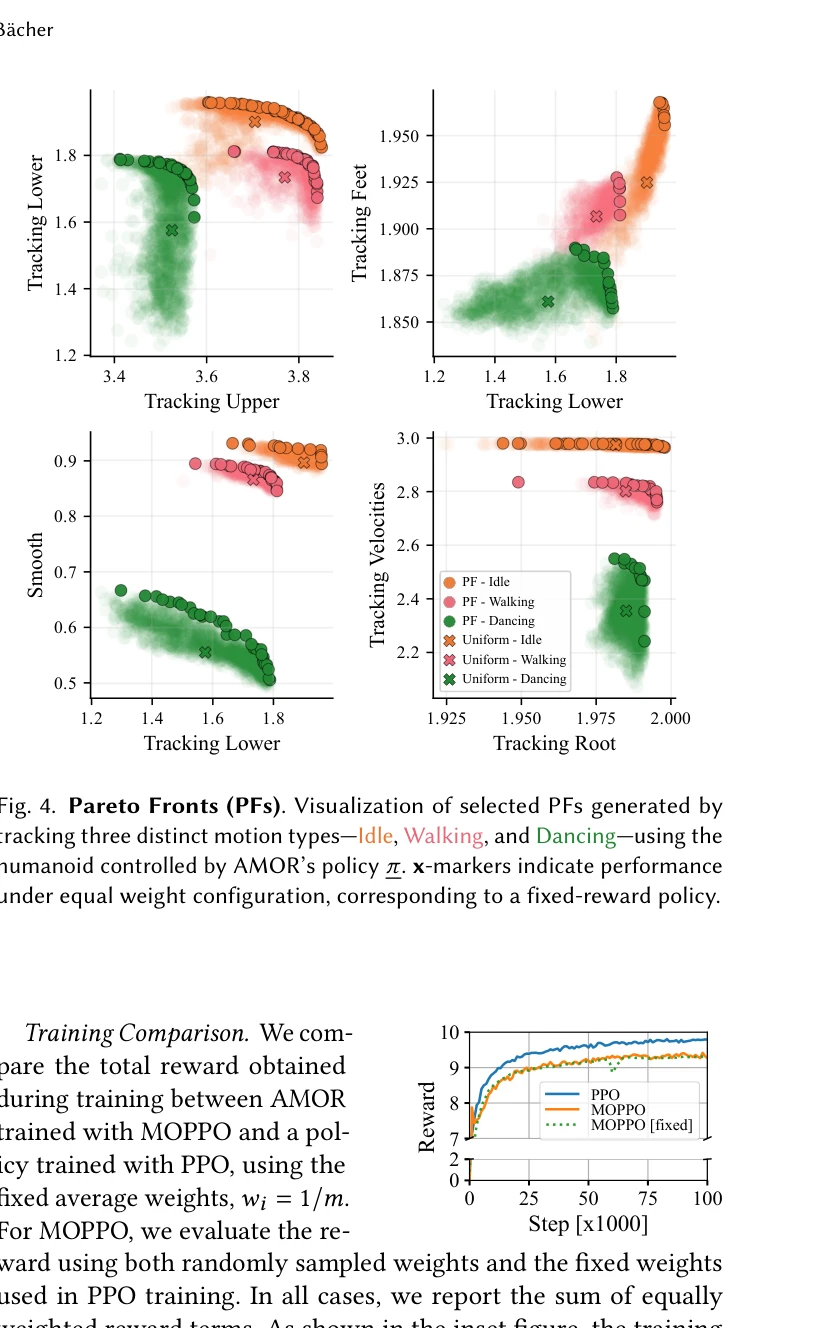
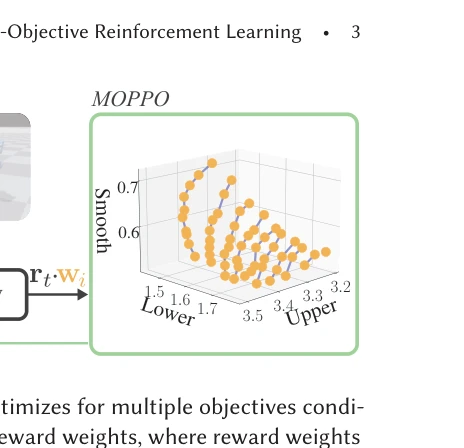
Essence
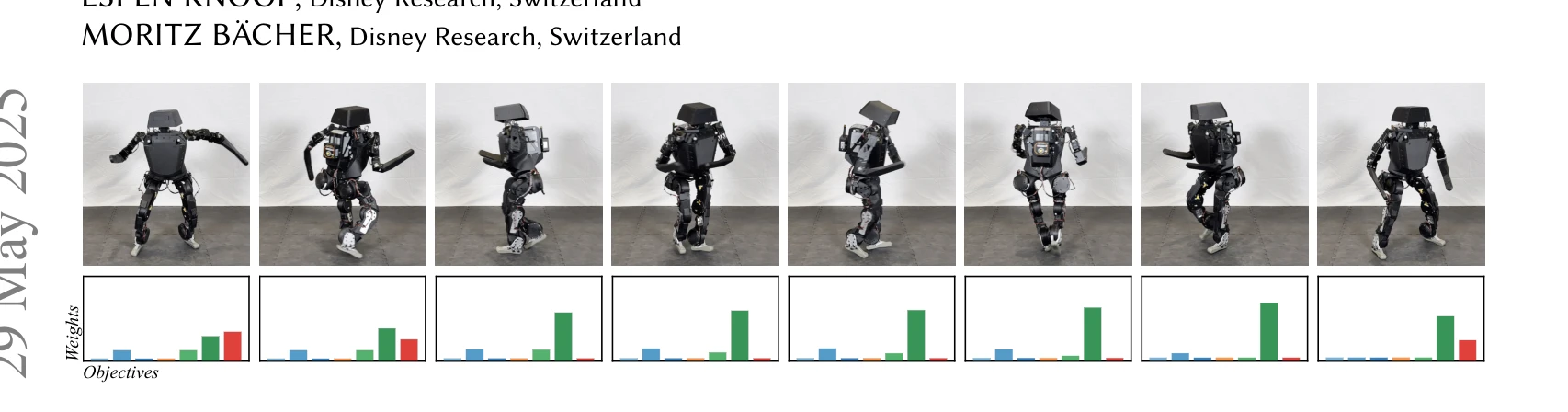
Fig. 1. Our method uses multi-objective reinforcement learning to enable on-the-fly tuning of reward weights post-traini
본 논문은 Multi-Objective Reinforcement Learning(MORL)을 활용하여 보상 함수의 가중치를 학습 후 조정할 수 있는 AMOR 프레임워크를 제안하며, 이를 통해 물리 기반 캐릭터 제어의 반복 튜닝 시간을 단축하고 실제 로봇으로의 전이를 용이하게 한다.