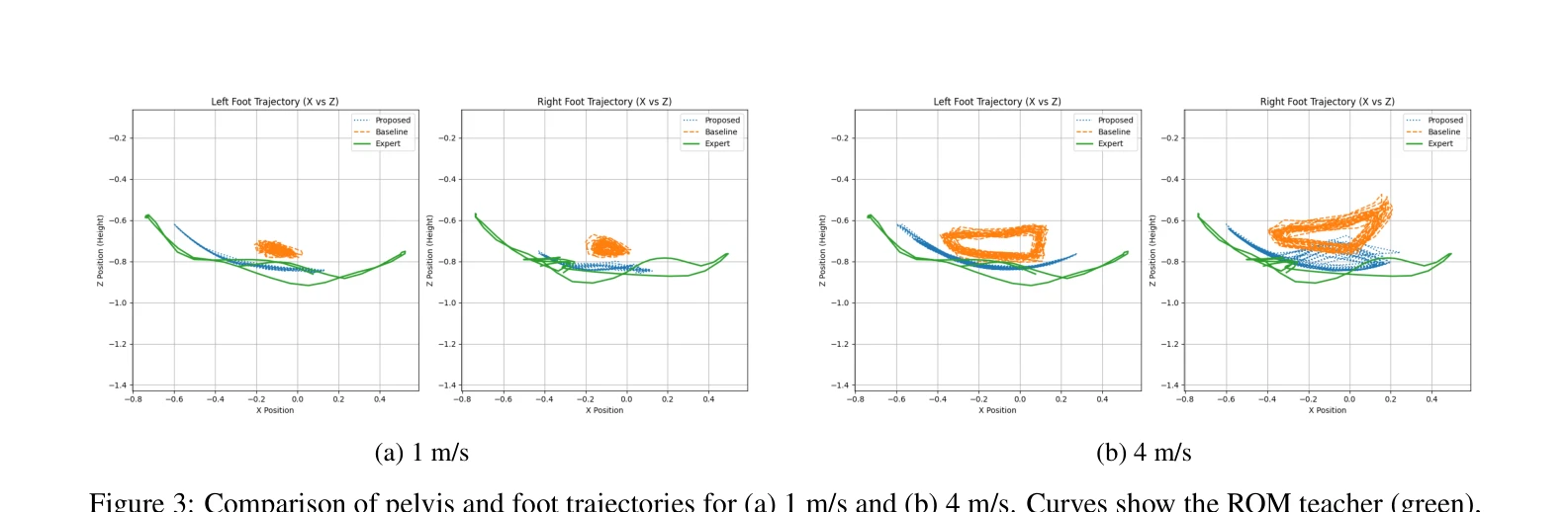
Essence
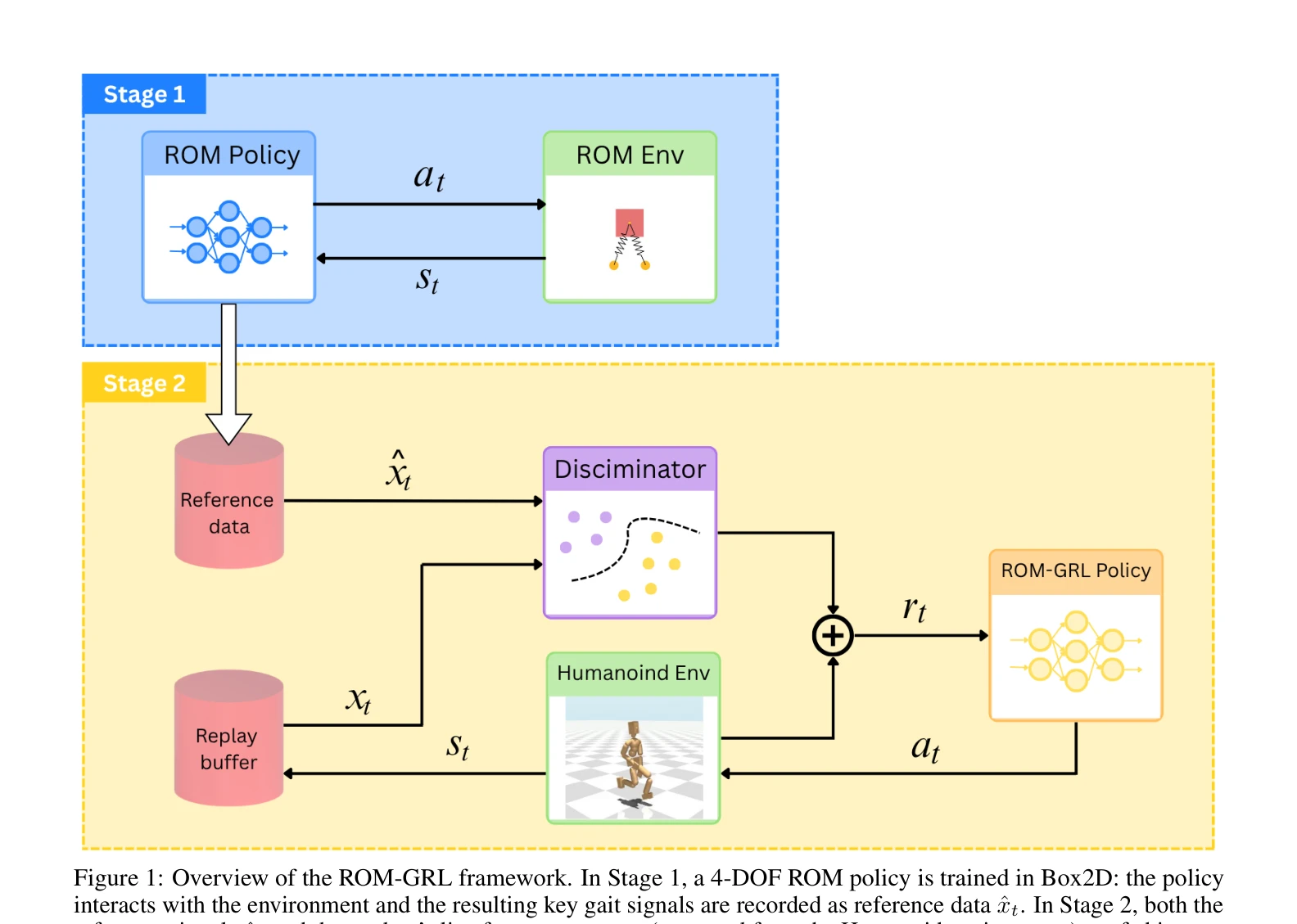
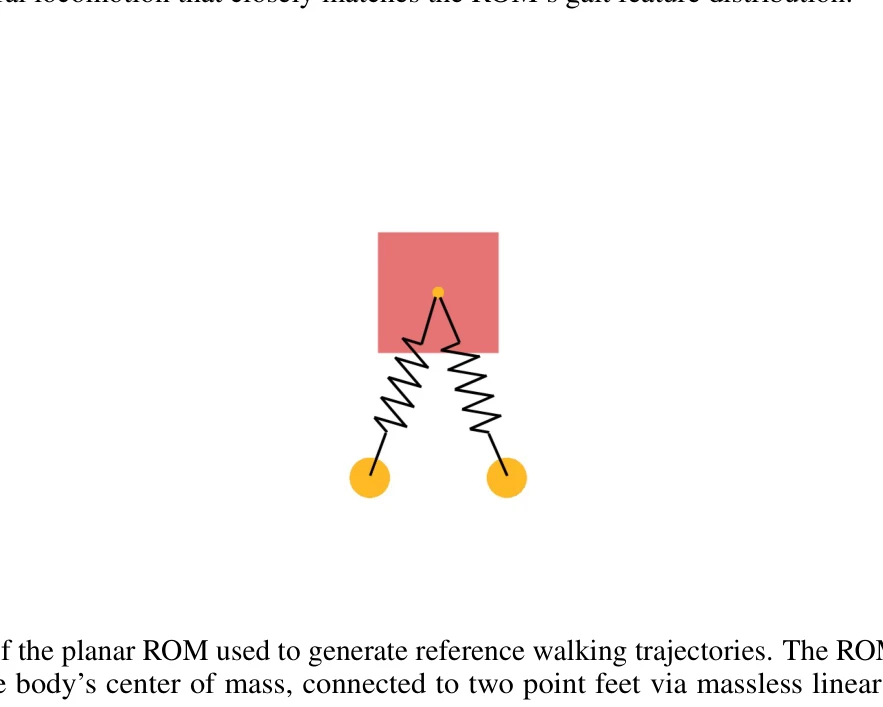
Figure 1: Overview of the ROM-GRL framework. In Stage 1, a 4-DOF ROM policy is trained in Box2D: the policy
ROM-GRL은 모션캡처 데이터 없이 4-DOF reduced-order model로 생성한 gait template을 이용해 full-body humanoid 정책을 학습하는 2단계 강화학습 프레임워크이다. Adversarial discriminator를 통해 ROM의 5-dimensional gait feature 분포를 따르도록 유도하여 자연스러운 보행을 실현한다.