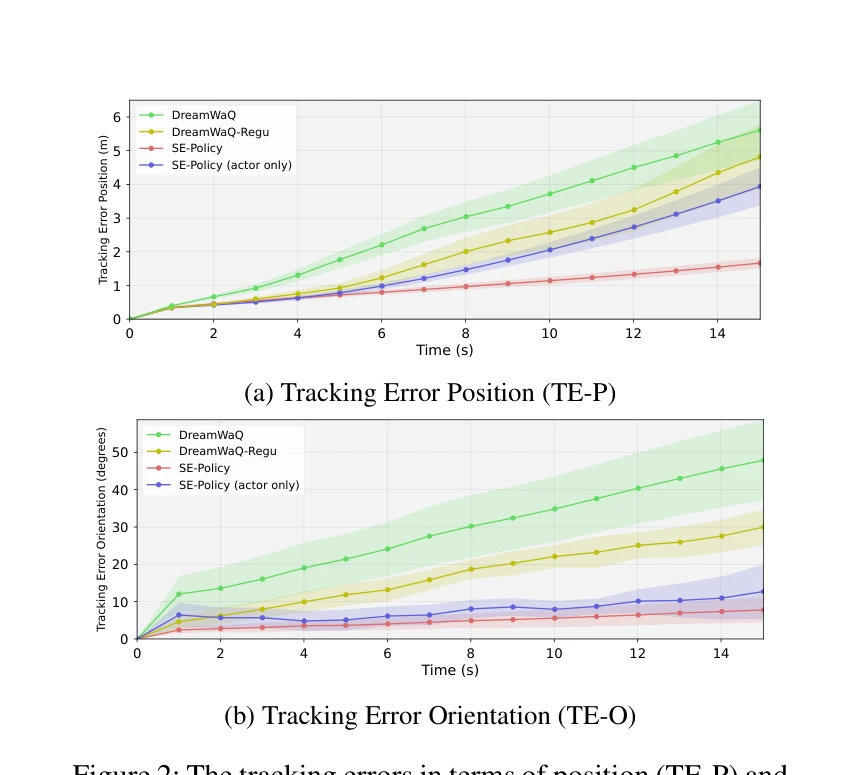
Essence
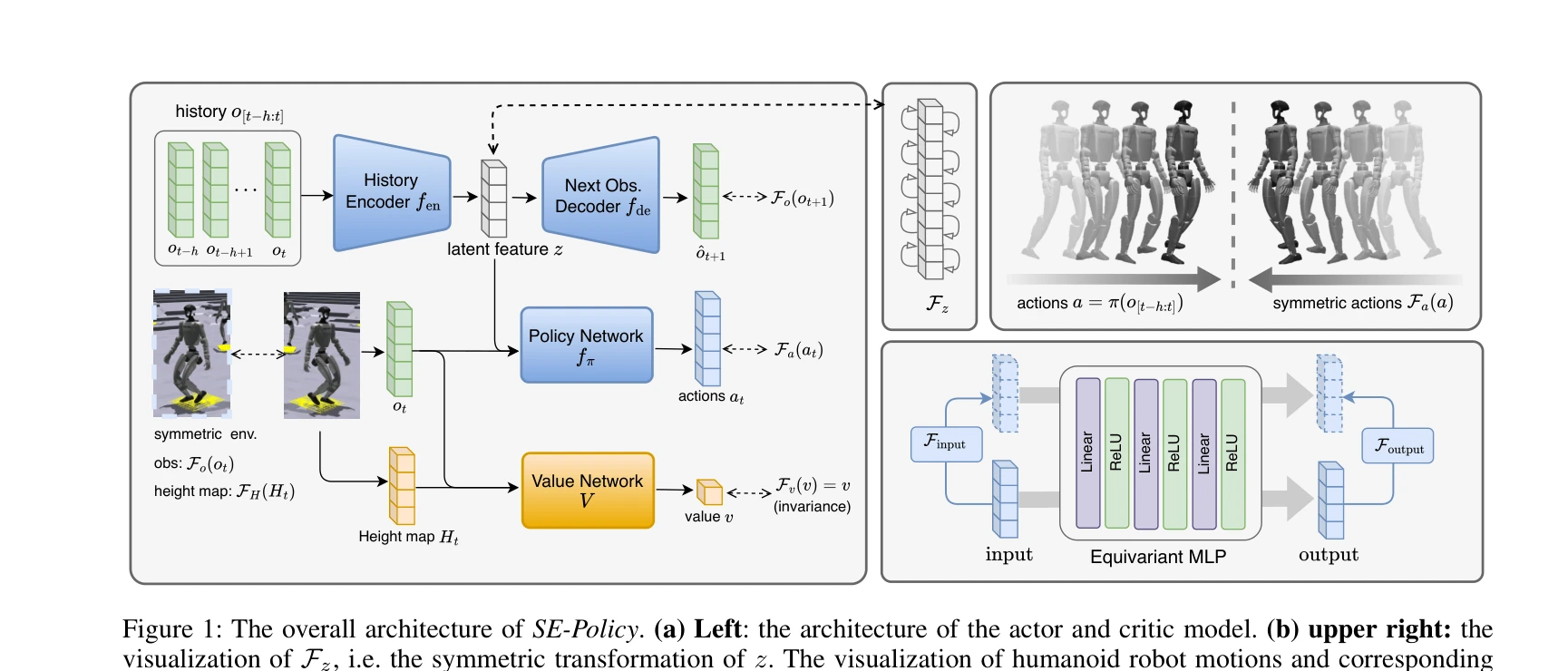
Figure 1: The overall architecture of SE-Policy. (a) Left: the architecture of the actor and critic model. (b) upper rig
인간의 신경계에서 영감을 받은 Symmetry Equivariant Policy (SE-Policy)를 제안하여, 휴머노이드 로봇의 형태적 대칭성을 DRL 프레임워크에 엄격하게 임베딩함으로써 조정되고 균형잡힌 보행을 실현한다.