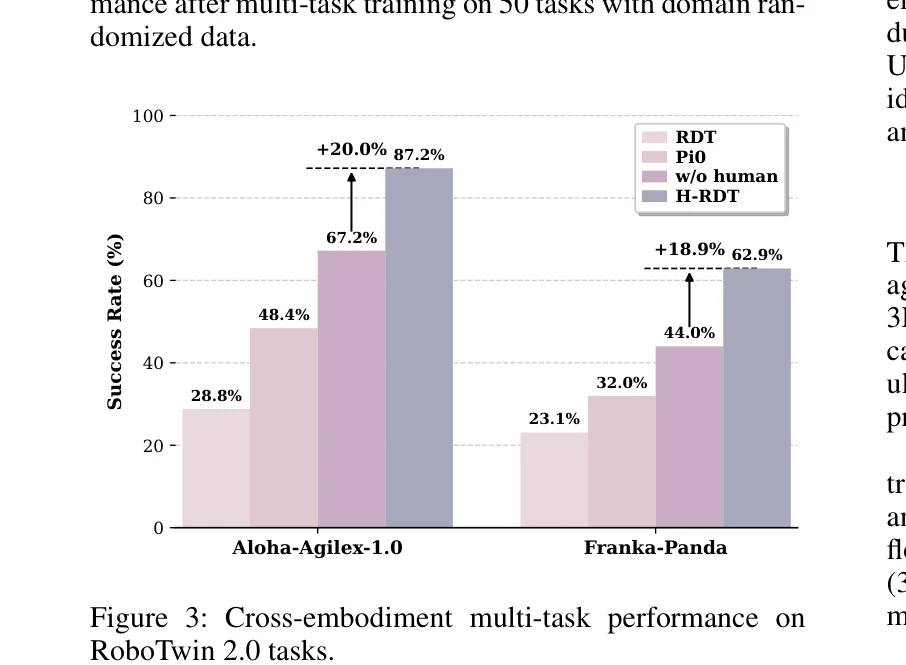
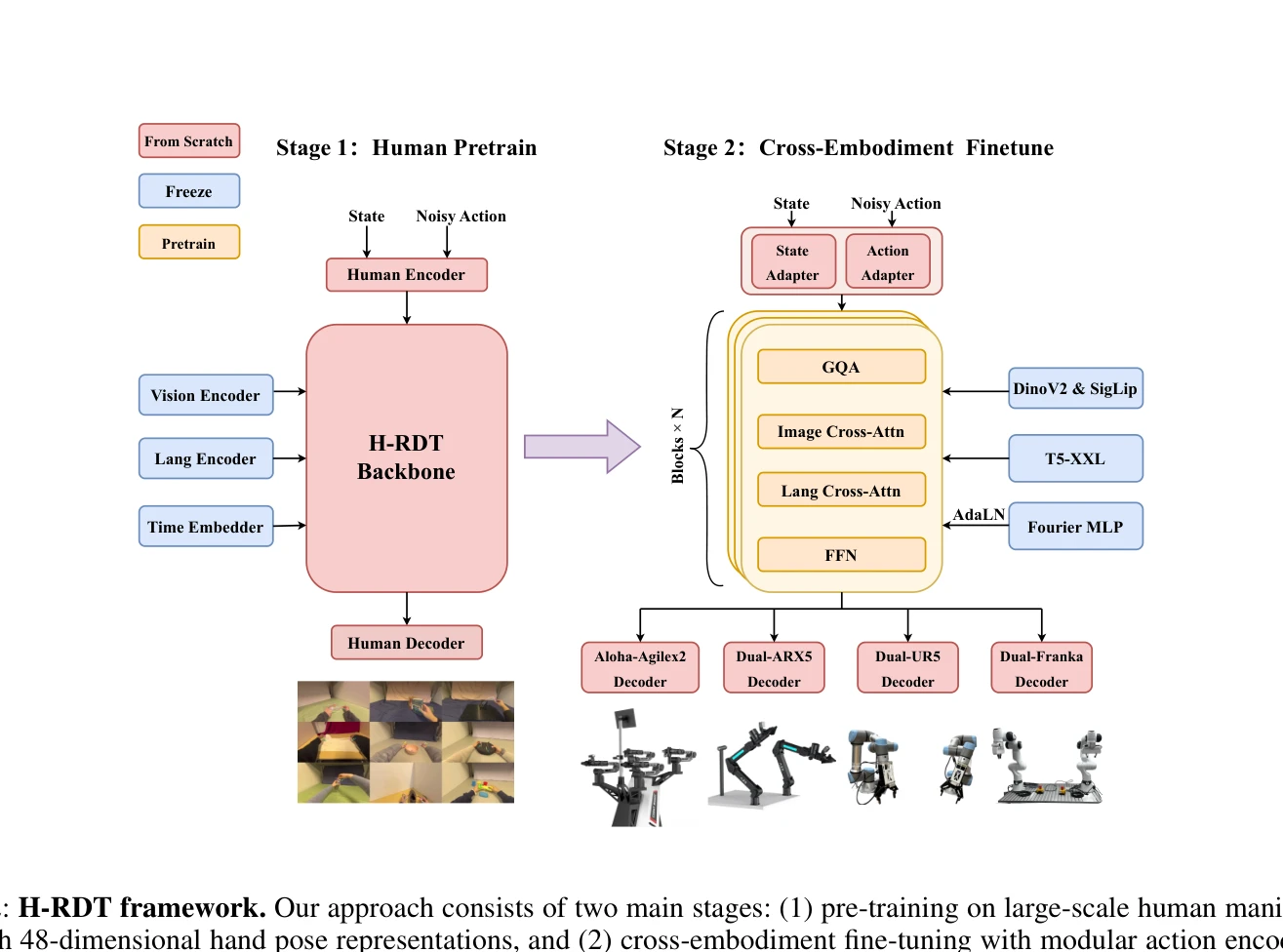
Essence
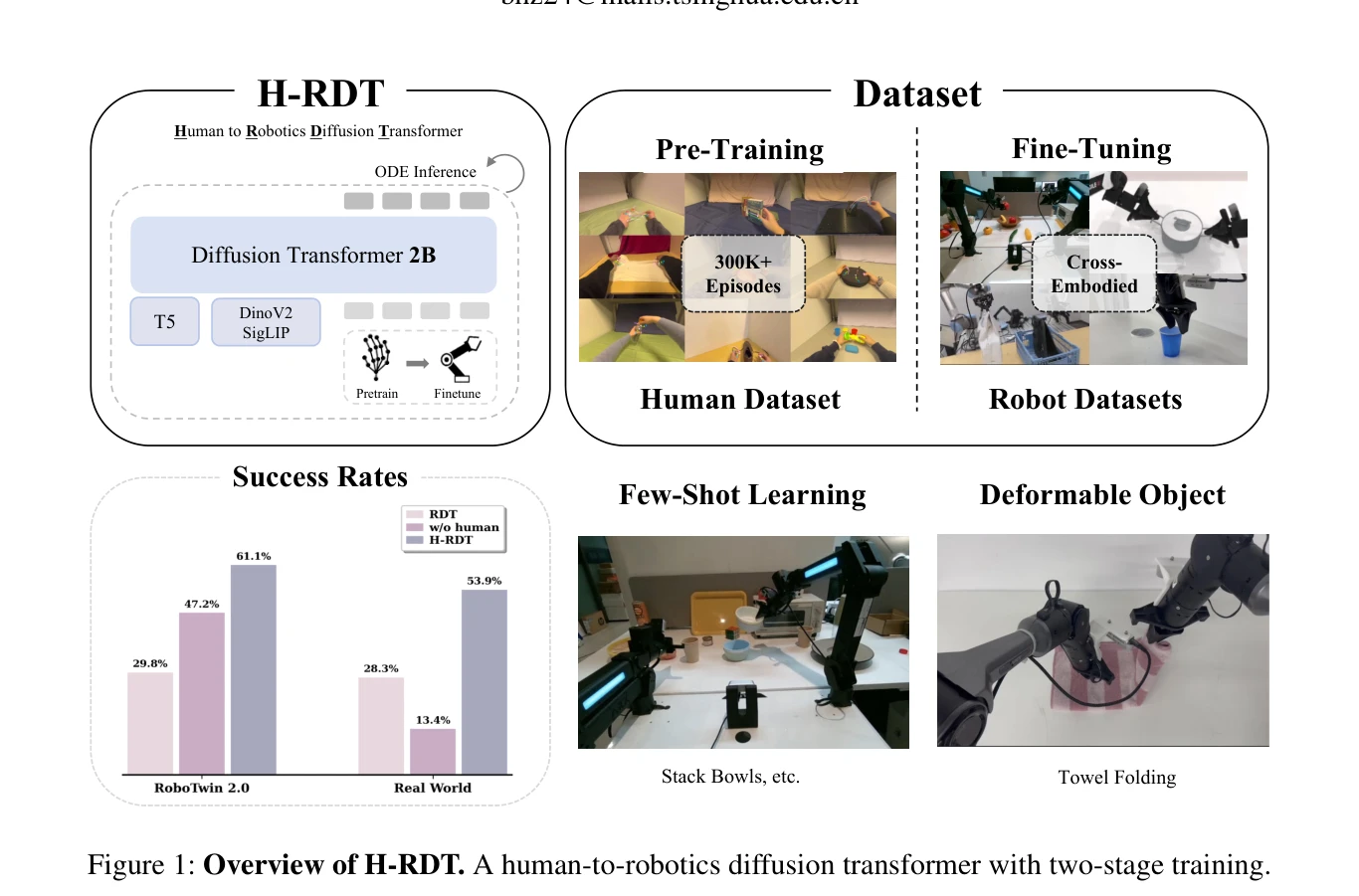
Figure 1: Overview of H-RDT. A human-to-robotics diffusion transformer with two-stage training.
H-RDT는 대규모 egocentric 인간 조작 데이터로 사전학습하고 모듈식 action encoder/decoder를 통해 다양한 로봇에 fine-tuning하는 두 단계 diffusion transformer 기반 접근법으로, 로봇 조작 학습을 향상시킨다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: H-RDT는 대규모 egocentric human manipulation 데이터의 가치를 체계적으로 입증하면서, 모듈식 전이 구조를 통해 diverse robot platform으로의 확장 가능성을 보여준 혁신적 연구이다. 광범위한 실험과 강력한 empirical 결과가 robotic manipulation 학습의 data scarcity 문제 해결에 실질적인 기여를 하고 있다.