저자: Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, Danfei Xu | 날짜: 2024-10-31 | URL: https://arxiv.org/abs/2410.24221 📄 PDF
Essence
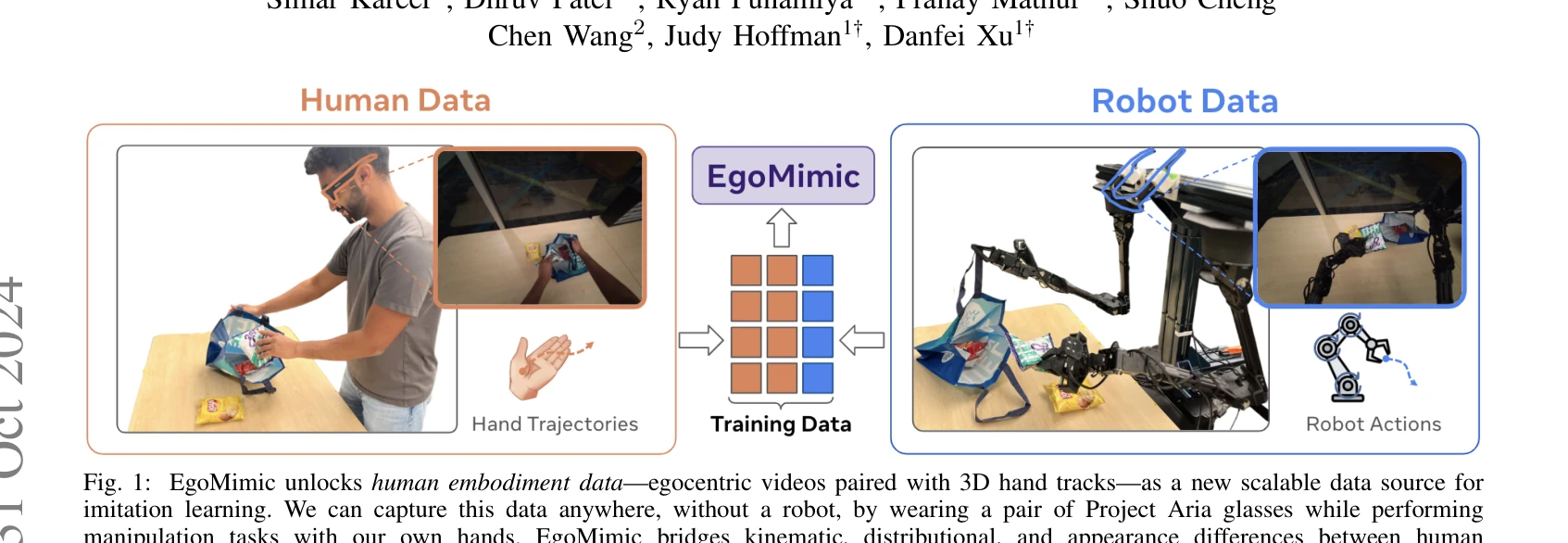
Fig. 1: EgoMimic unlocks human embodiment data—egocentric videos paired with 3D hand tracks—as a new scalable data sourc
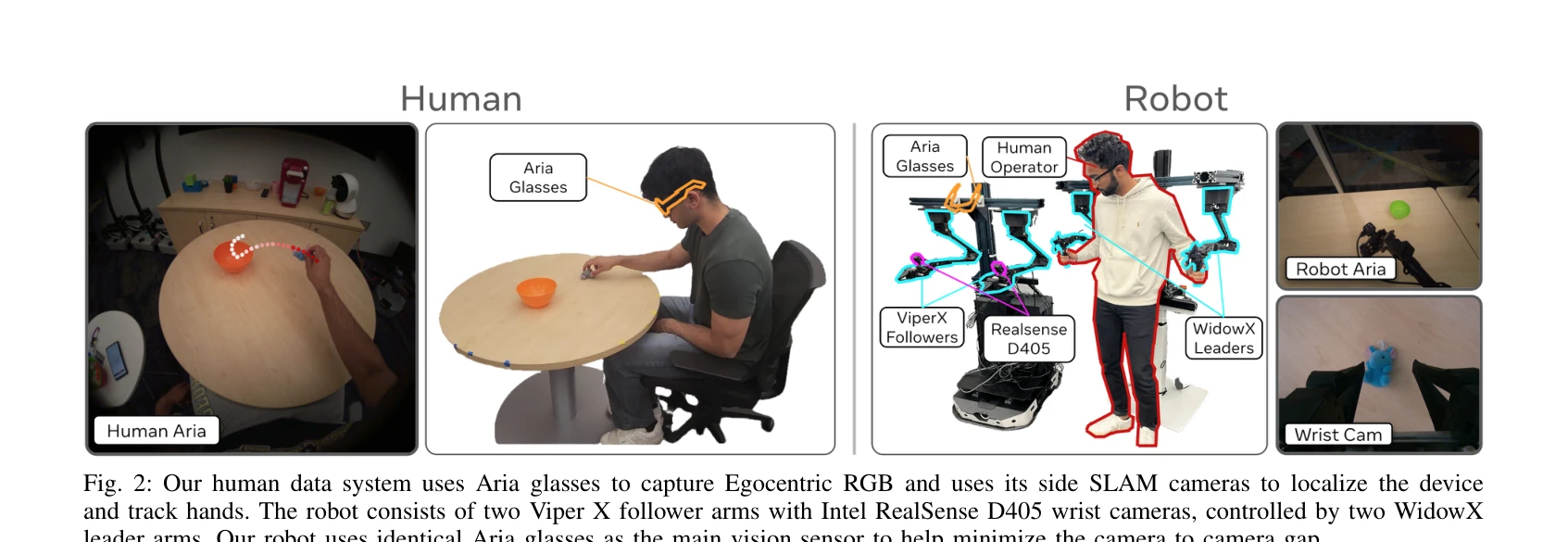
EgoMimic은 Project Aria 안경을 통해 수집한 인간의 일인칭 시점 비디오와 3D 손 추적 데이터를 로봇 조작 학습에 활용하는 전체 스택 프레임워크로, 인간과 로봇 데이터를 동등한 embodied demonstration으로 취급하여 통합 정책을 학습한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: EgoMimic은 인간의 일인칭 시점 데이터를 로봇 학습에 동등하게 활용하는 혁신적 접근으로, 실제 조작 작업에서 뛰어난 성능 개선과 일반화를 입증했으며, 수동적 대규모 데이터 수집의 가능성을 열어 로봇 학습의 확장성 문제 해결에 크게 기여한다.