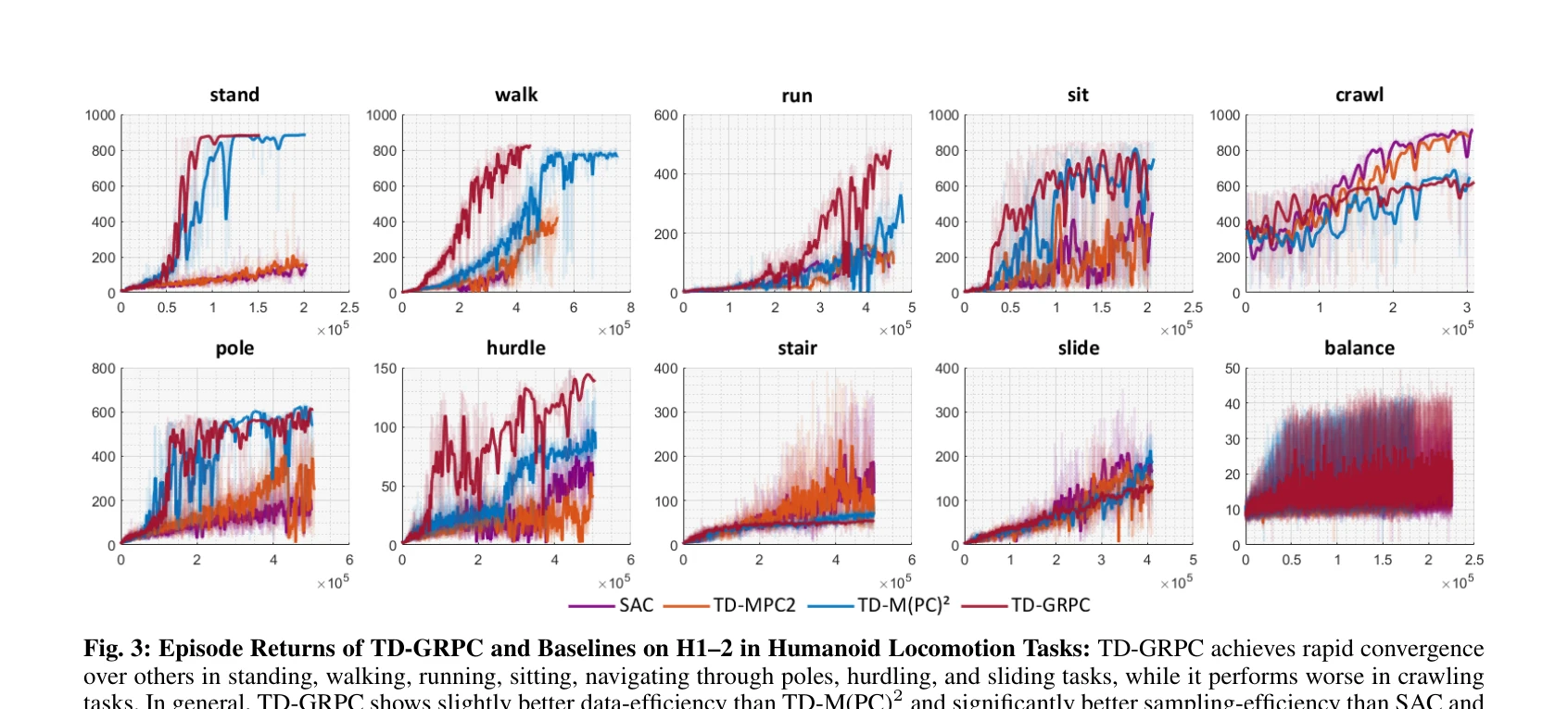
Essence
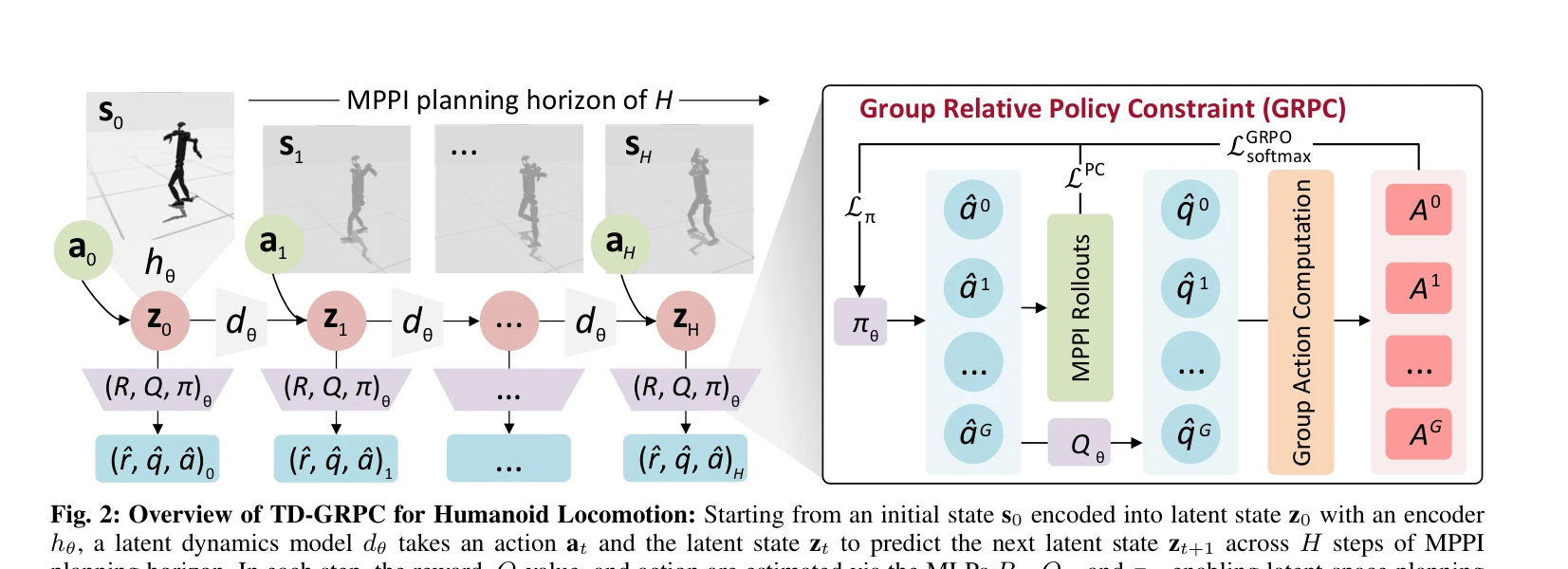
Fig. 2: Overview of TD-GRPC for Humanoid Locomotion: Starting from an initial state s0 encoded into latent state z0 with
본 논문은 Humanoid Locomotion을 위해 TD-MPC 프레임워크에 Group Relative Policy Optimization (GRPO)와 trust-region constraint를 통합한 TD-GRPC를 제안하여, off-policy 학습의 불안정성과 policy mismatch 문제를 해결한다.