저자: Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, Chuang Gan | 날짜: 2024-03-14 | URL: https://arxiv.org/abs/2403.09631 📄 PDF
Essence
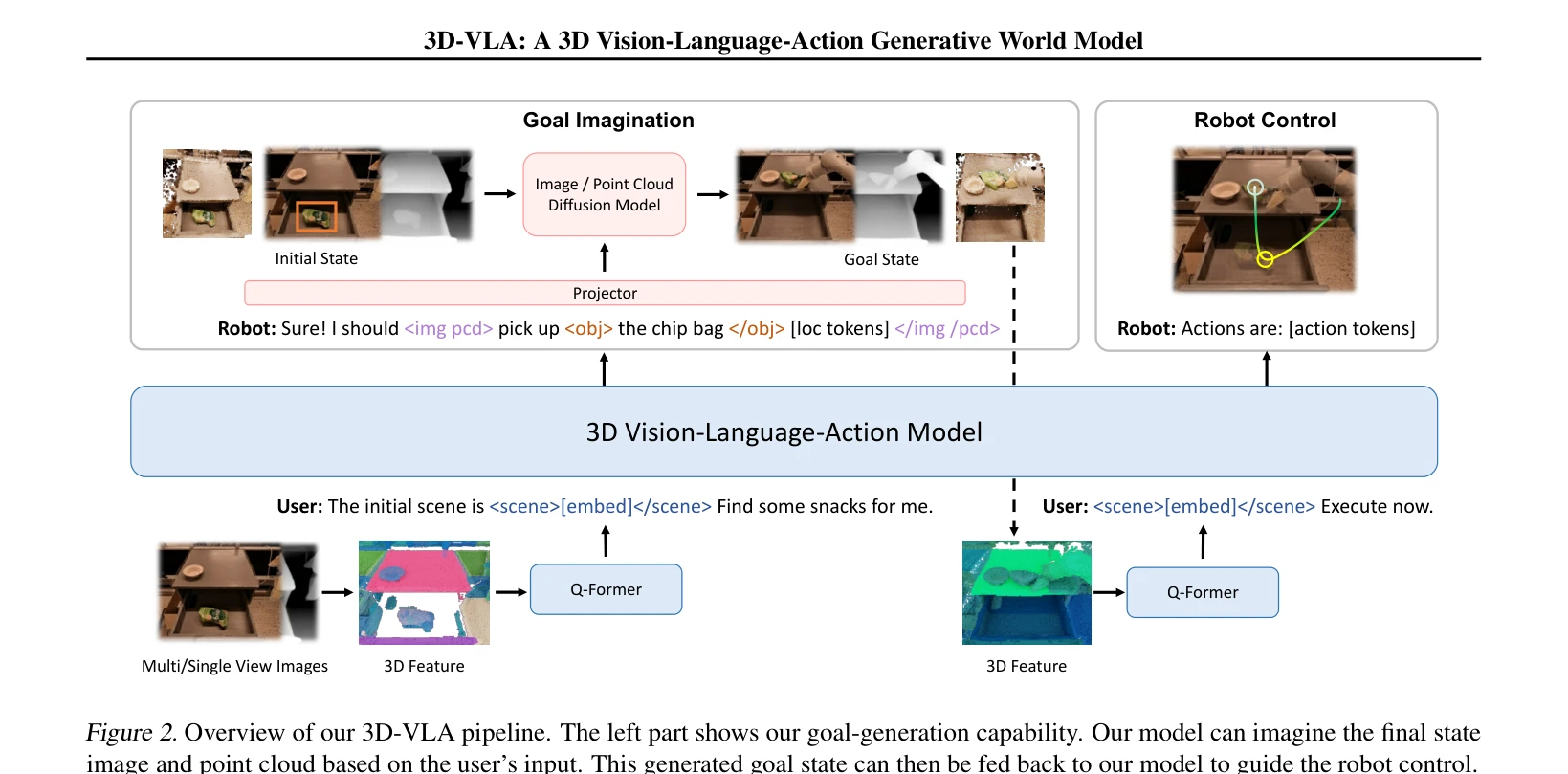
Figure 2. Overview of our 3D-VLA pipeline. The left part shows our goal-generation capability. Our model can imagine the
3D-VLA는 3D 인식, 추론, 행동을 생성형 월드 모델로 통합하는 embodied foundation model이며, 3D LLM 위에 interaction token과 diffusion model을 결합하여 로봇의 목표 이미지/포인트 클라우드 생성과 행동 예측을 수행한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 3D-VLA는 embodied AI의 새로운 패러다임을 제시하며, 3D 인식과 월드 모델 기반 행동 생성을 통합한 점에서 혁신적이다. 대규모 3D embodied 데이터셋 구축과 multimodal goal generation 능력은 로봇 조작 분야에 상당한 기여를 할 수 있으나, 실제 로봇 환경에서의 검증이 필요하다.
