Essence
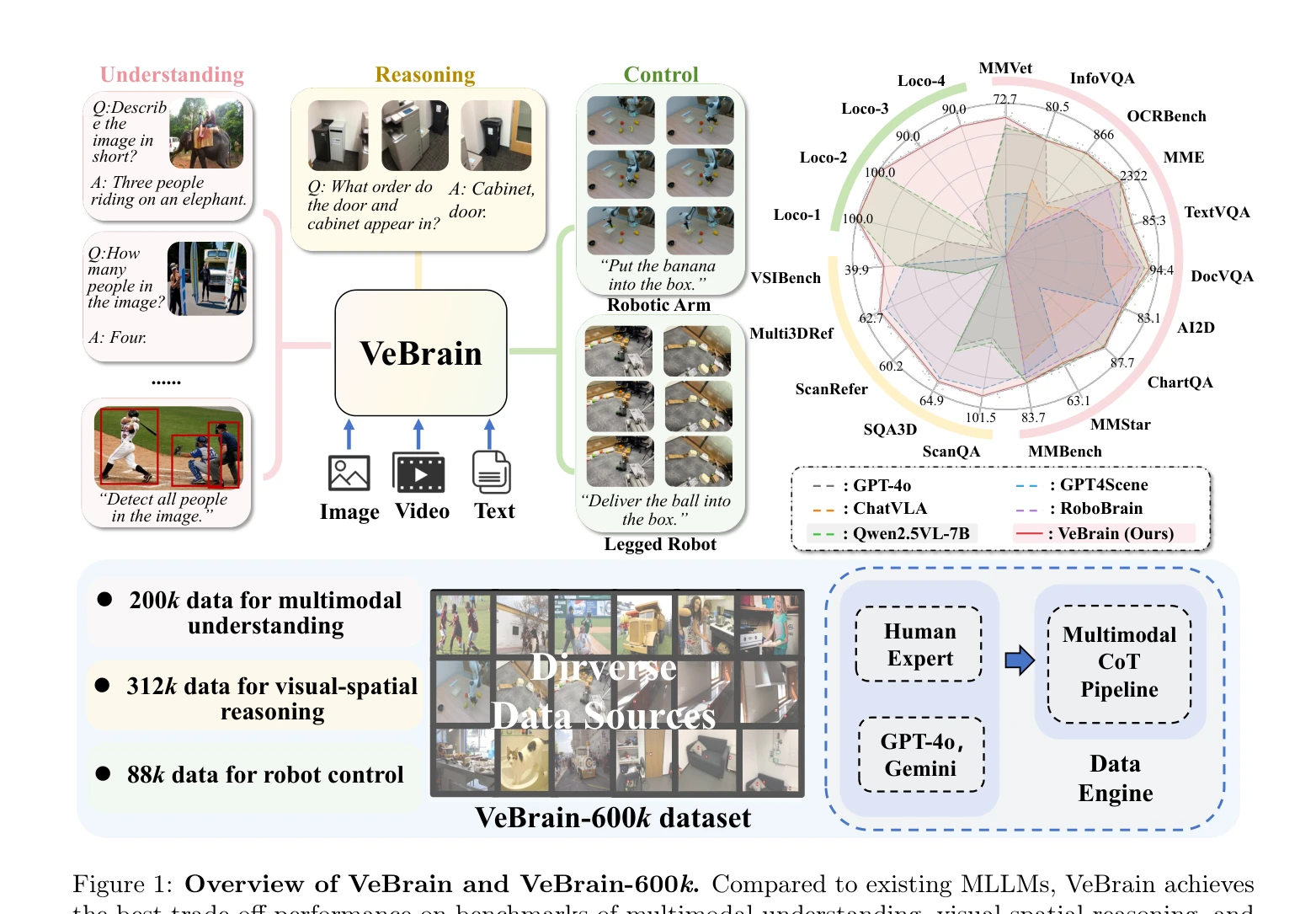
Figure 1: Overview of VeBrain and VeBrain-600k. Compared to existing MLLMs, VeBrain achieves
VeBrain은 멀티모달 대형 언어 모델(MLLM)을 지각, 추론, 제어 기능으로 통합하는 프레임워크이며, 로봇 제어 작업을 2D 시각 공간의 텍스트 기반 MLLM 작업으로 재구성합니다.
저자: Gen Luo, Ganlin Yang, Ziyang Gong, Guanzhou Chen, Haonan Duan, Erfei Cui, Ronglei Tong, Zhi Hou, Tianyi Zhang, Zhe Chen, Shenglong Ye, Lewei Lu, Jingbo Wang, Wenhai Wang, Jifeng Dai, Yu Qiao, Rongrong Ji, Xizhou Zhu | 날짜: 2025-05-30 | URL: https://arxiv.org/abs/2506.00123 📄 PDF
Figure 1: Overview of VeBrain and VeBrain-600k. Compared to existing MLLMs, VeBrain achieves
VeBrain은 멀티모달 대형 언어 모델(MLLM)을 지각, 추론, 제어 기능으로 통합하는 프레임워크이며, 로봇 제어 작업을 2D 시각 공간의 텍스트 기반 MLLM 작업으로 재구성합니다.
Figure 1: Overview of VeBrain and VeBrain-600k. Compared to existing MLLMs, VeBrain achieves
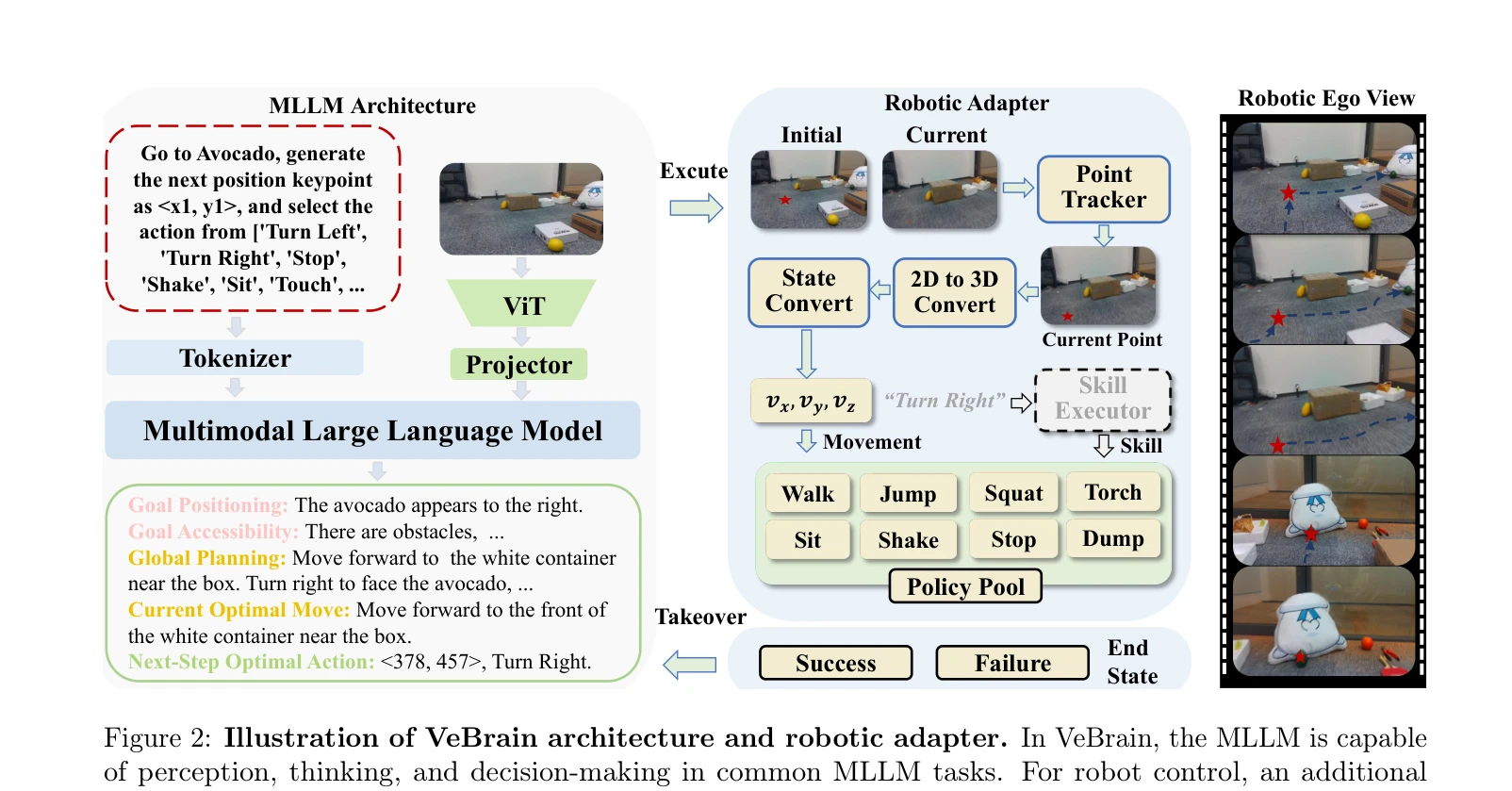
Figure 2: Illustration of VeBrain architecture and robotic adapter. In VeBrain, the MLLM is capable
총평: VeBrain은 멀티모달 이해와 로봇 제어를 2D 시각 공간의 공통 MLLM 작업으로 통합하는 혁신적인 접근으로, 광범위한 벤치마크와 로봇 실험에서 우수한 성능을 입증하며 구체화된 AI의 중요한 진전을 나타냅니다.