Essence
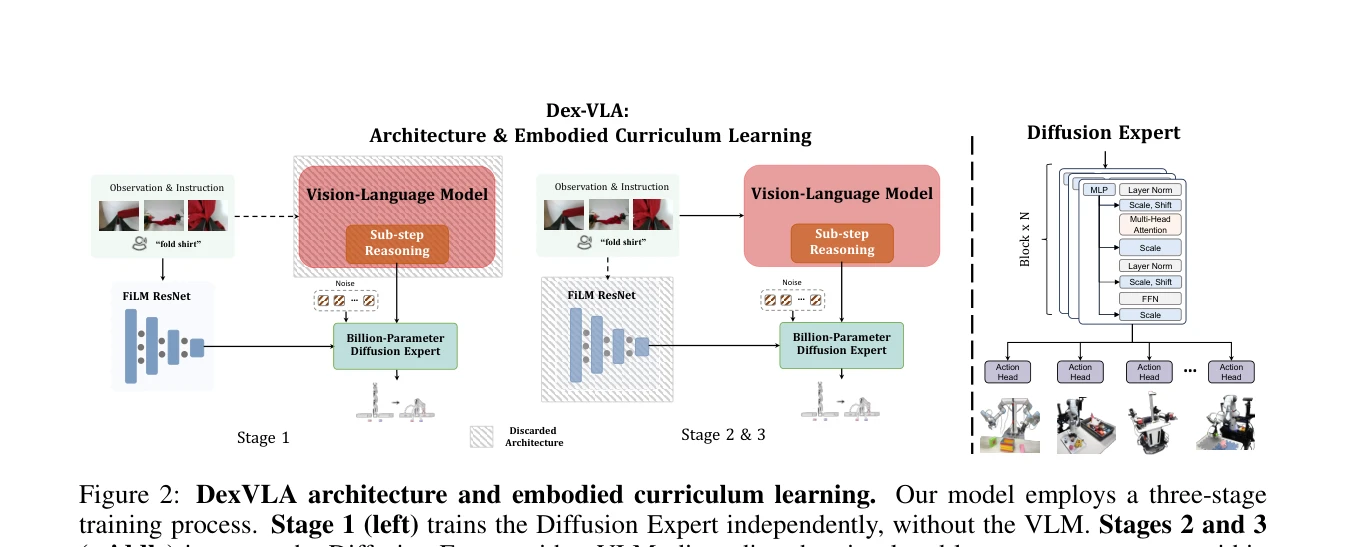
Figure 2: DexVLA architecture and embodied curriculum learning. Our model employs a three-stage
DexVLA는 billion 규모의 diffusion-based action expert를 plug-in 형태로 vision-language model에 통합하고, 3단계 embodied curriculum learning 전략을 통해 다양한 로봇 형태에서 복잡한 long-horizon task를 수행할 수 있는 VLA 프레임워크를 제안한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: DexVLA는 diffusion-based action expert의 plug-in 설계와 embodied curriculum learning 전략으로 VLA의 효율성과 일반화 능력을 크게 향상시킨 작업이다. 특히 external high-level policy 없이 복잡한 long-horizon task를 직접 수행할 수 있다는 점과 제한된 데이터로 다양한 로봇에 적응할 수 있다는 점이 현실적 가치가 높으나, 공정한 비교 실험과 더 광범위한 task 검증이 필요하다.
