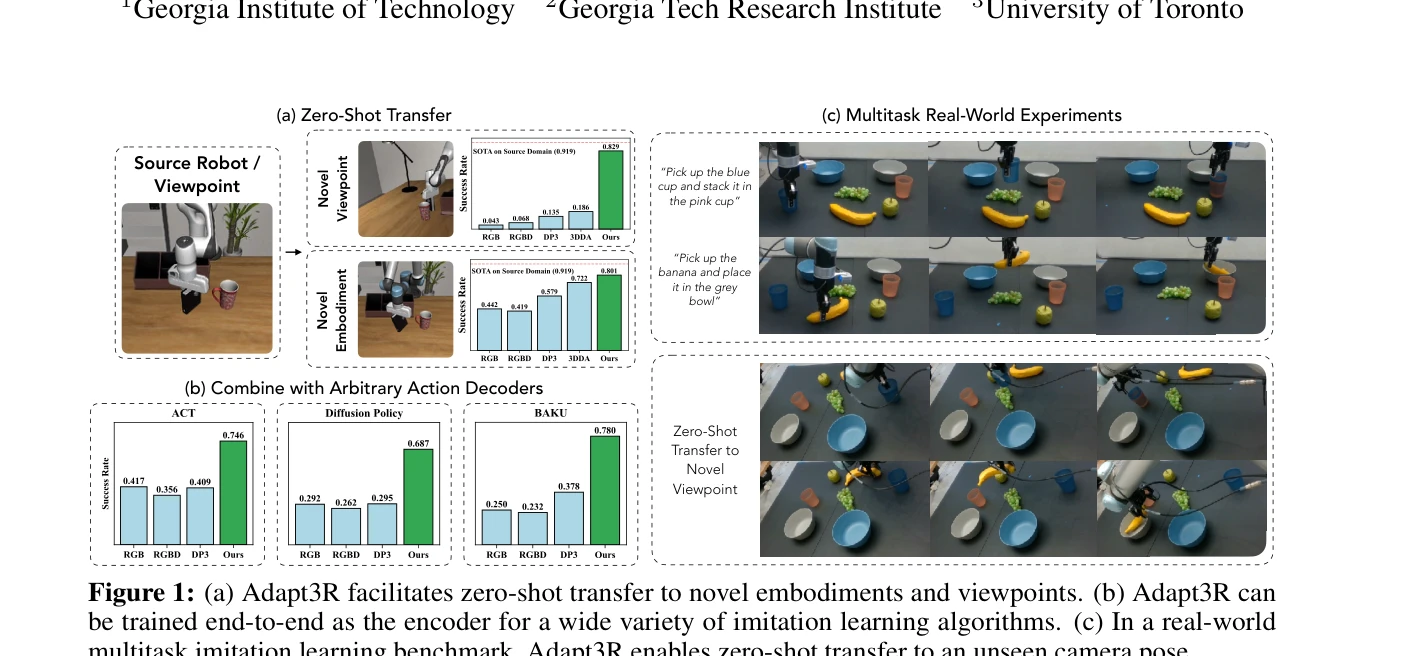
Essence
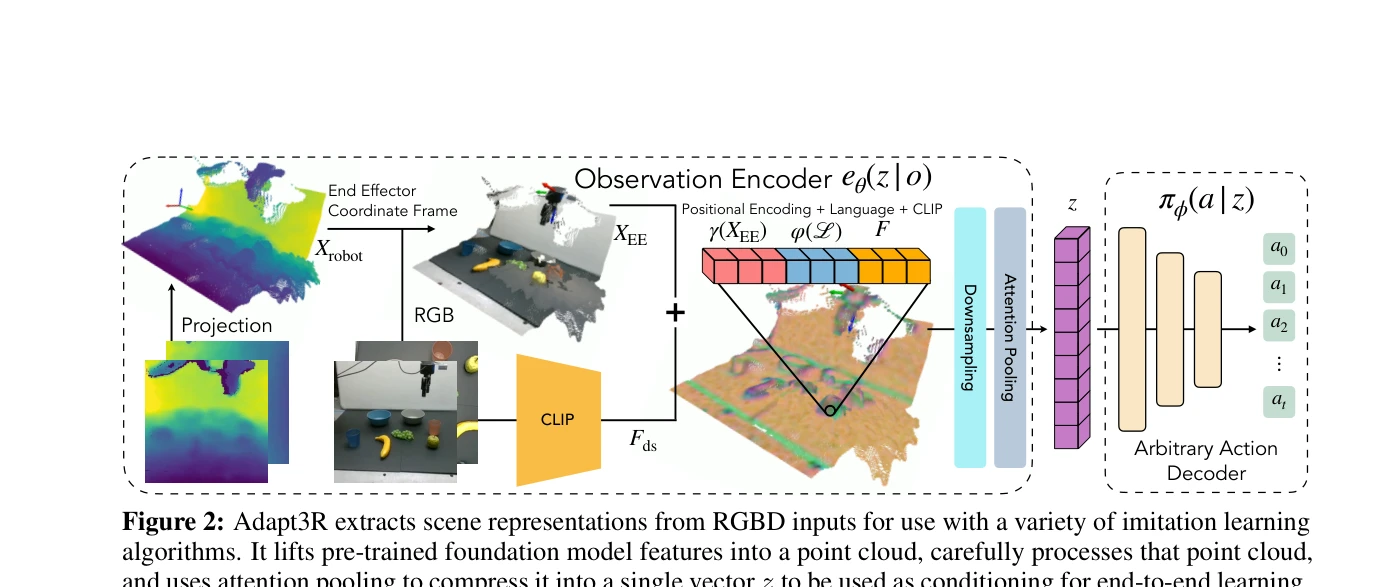
Figure 2: Adapt3R extracts scene representations from RGBD inputs for use with a variety of imitation learning
Adapt3R는 calibrated RGBD 카메라로부터 3D 장면 표현을 추출하여 모방 학습(IL) 알고리즘의 조건으로 사용하는 관찰 인코더이며, pretrained 2D backbone으로 의미론적 정보를 추출하고 3D 정보는 end-effector에 상대적인 localization에만 사용하여 novel embodiment과 camera viewpoint으로의 zero-shot transfer를 실현한다.