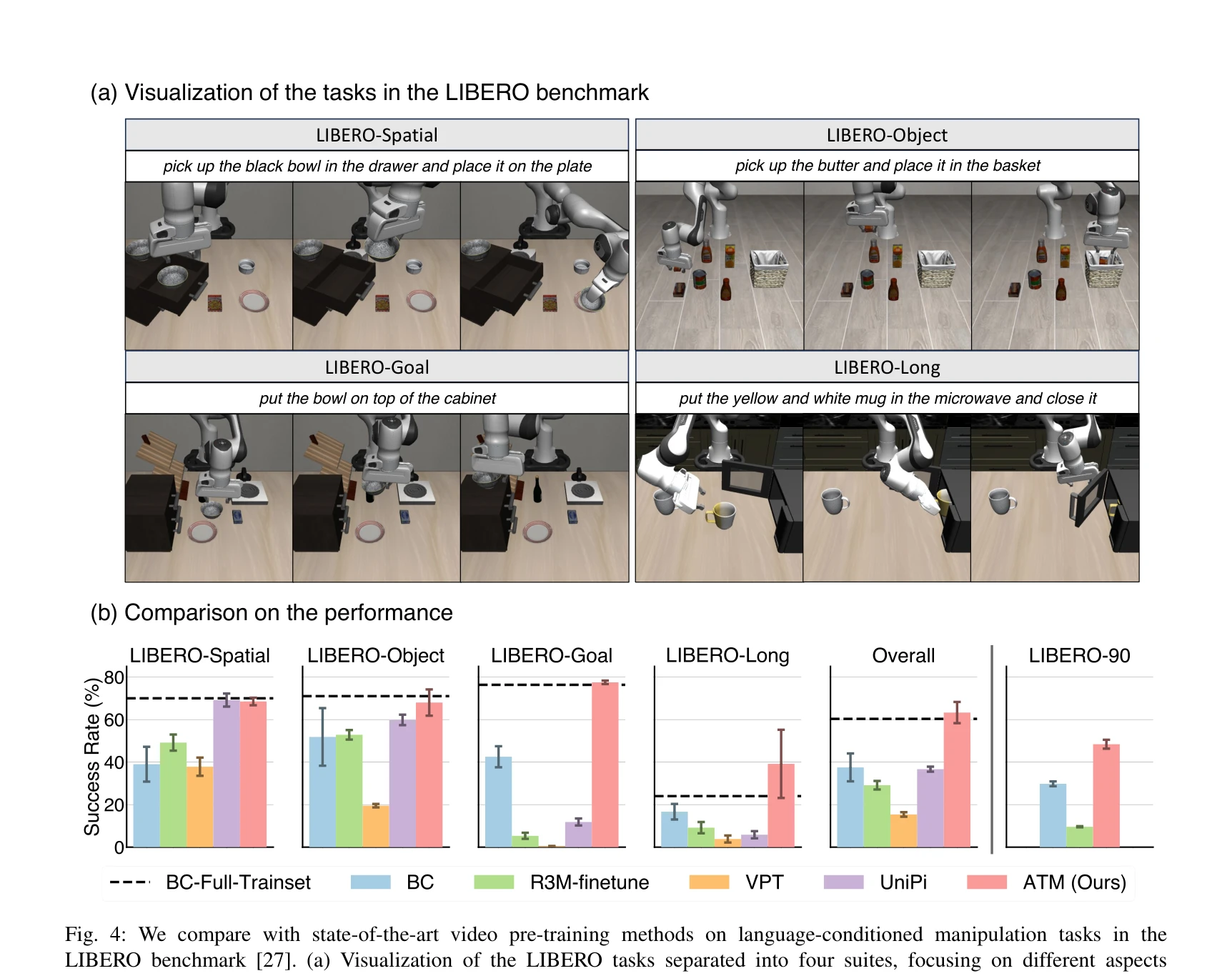
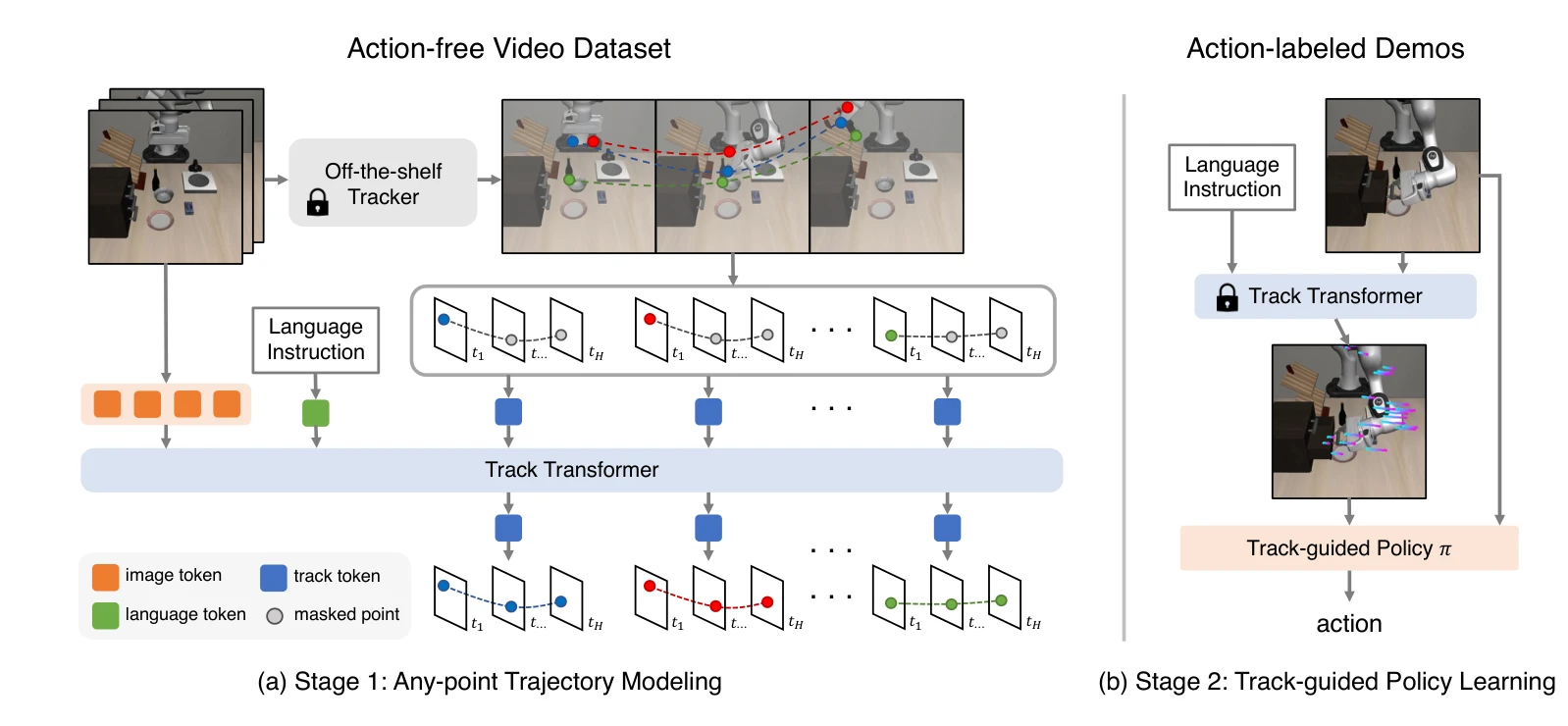
Essence
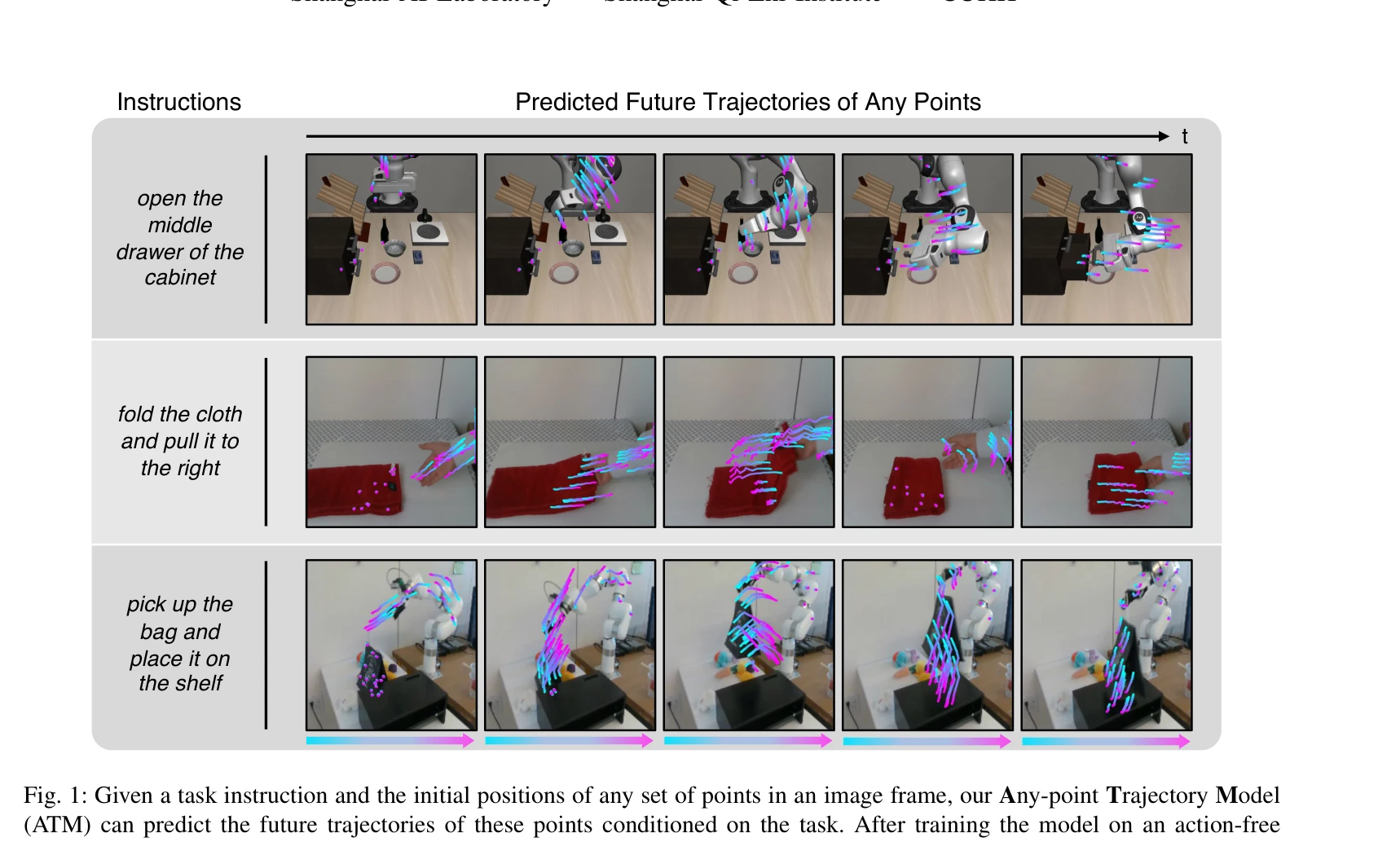
Fig. 1: Given a task instruction and the initial positions of any set of points in an image frame, our Any-point Traject
Any-point Trajectory Modeling (ATM)은 액션 라벨이 없는 비디오에서 임의의 점들의 미래 궤적을 예측하도록 사전 학습된 궤적 모델을 활용하여, 최소한의 액션-라벨 데이터로도 강건한 visuomotor 정책 학습을 가능하게 하는 프레임워크이다.