Essence
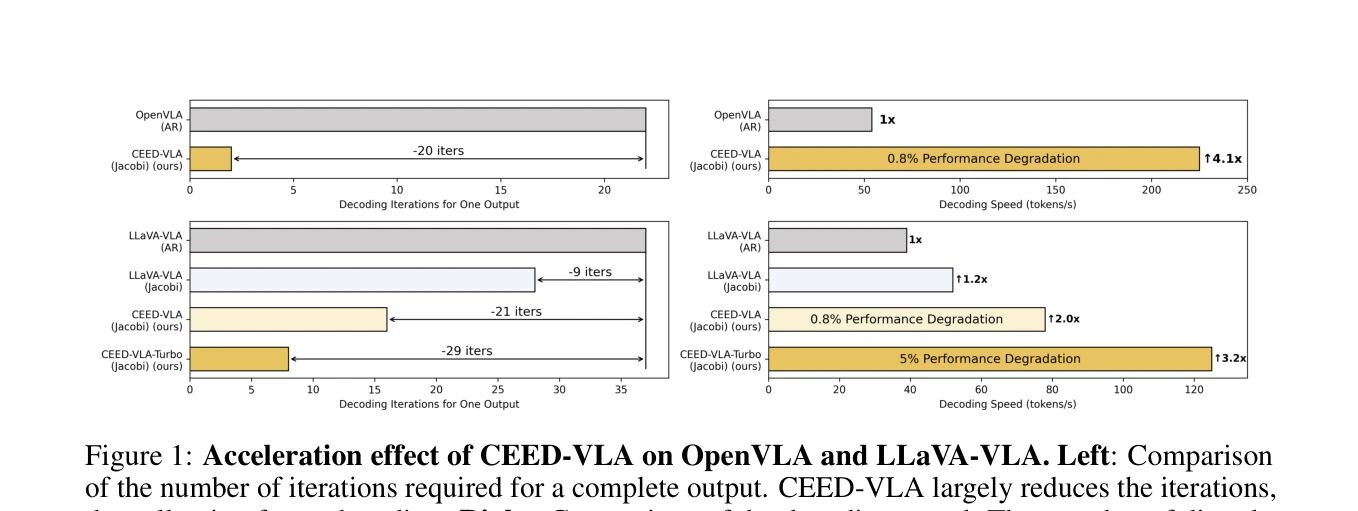
Figure 1: Acceleration effect of CEED-VLA on OpenVLA and LLaVA-VLA. Left: Comparison
Vision-Language-Action (VLA) 모델의 추론 속도를 향상시키기 위해 consistency distillation과 early-exit decoding을 결합한 CEED-VLA를 제안하며, 4배 이상의 가속화를 달성한다.
저자: Wenxuan Song, Jiayi Chen, Pengxiang Ding, Yuxin Huang, Han Zhao, Donglin Wang, Haoang Li | 날짜: 2025-06-16 | URL: https://arxiv.org/abs/2506.13725 📄 PDF
Figure 1: Acceleration effect of CEED-VLA on OpenVLA and LLaVA-VLA. Left: Comparison
Vision-Language-Action (VLA) 모델의 추론 속도를 향상시키기 위해 consistency distillation과 early-exit decoding을 결합한 CEED-VLA를 제안하며, 4배 이상의 가속화를 달성한다.
Figure 1: Acceleration effect of CEED-VLA on OpenVLA and LLaVA-VLA. Left: Comparison
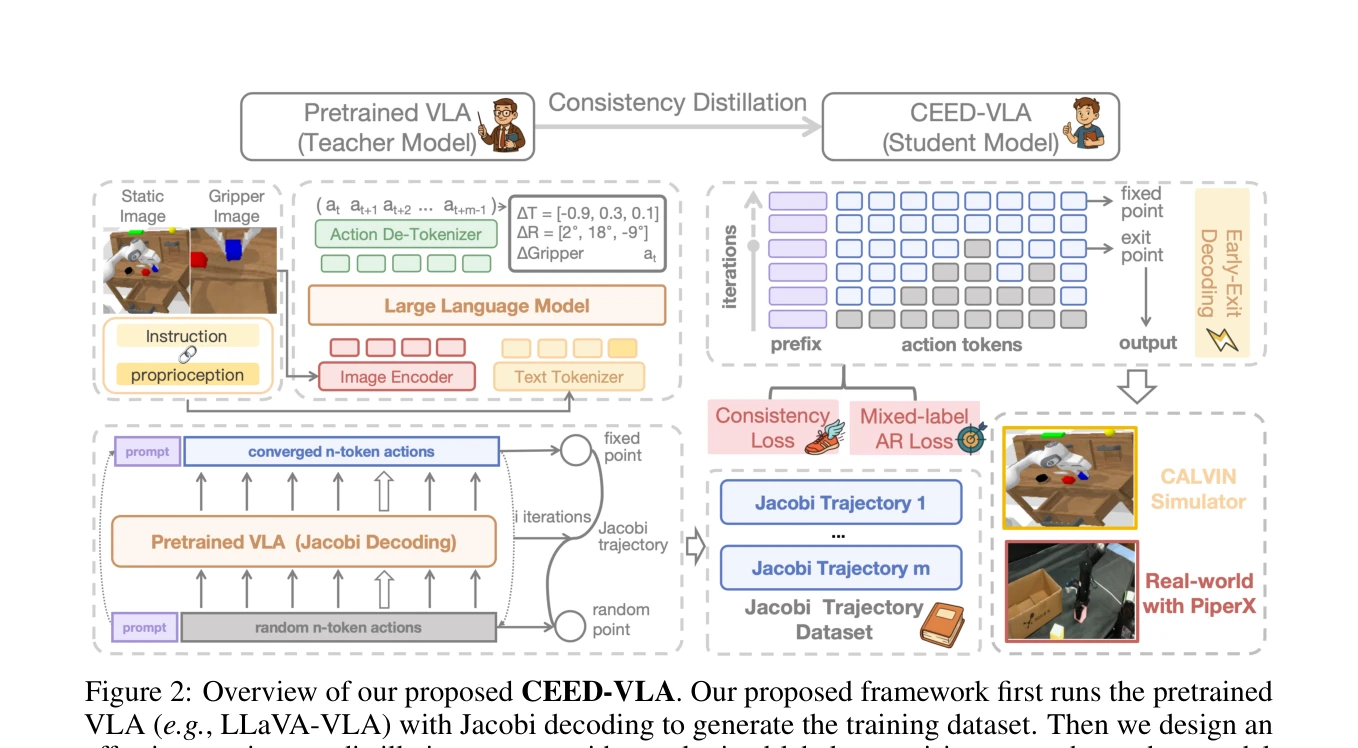
Figure 2: Overview of our proposed CEED-VLA. Our proposed framework first runs the pretrained
총평: CEED-VLA는 consistency distillation과 early-exit decoding을 결합하여 VLA 추론을 획기적으로 가속화하며, 실제 로봇 배포에서 4배 이상의 속도 개선을 달성하면서도 조작 성능을 유지하는 실용적이고 일반화 가능한 해결책을 제시한다.