Essence

Figure 1: Diverse Capabilities of CorrectNav. The model takes only monocular RGB video and language instructions as inpu
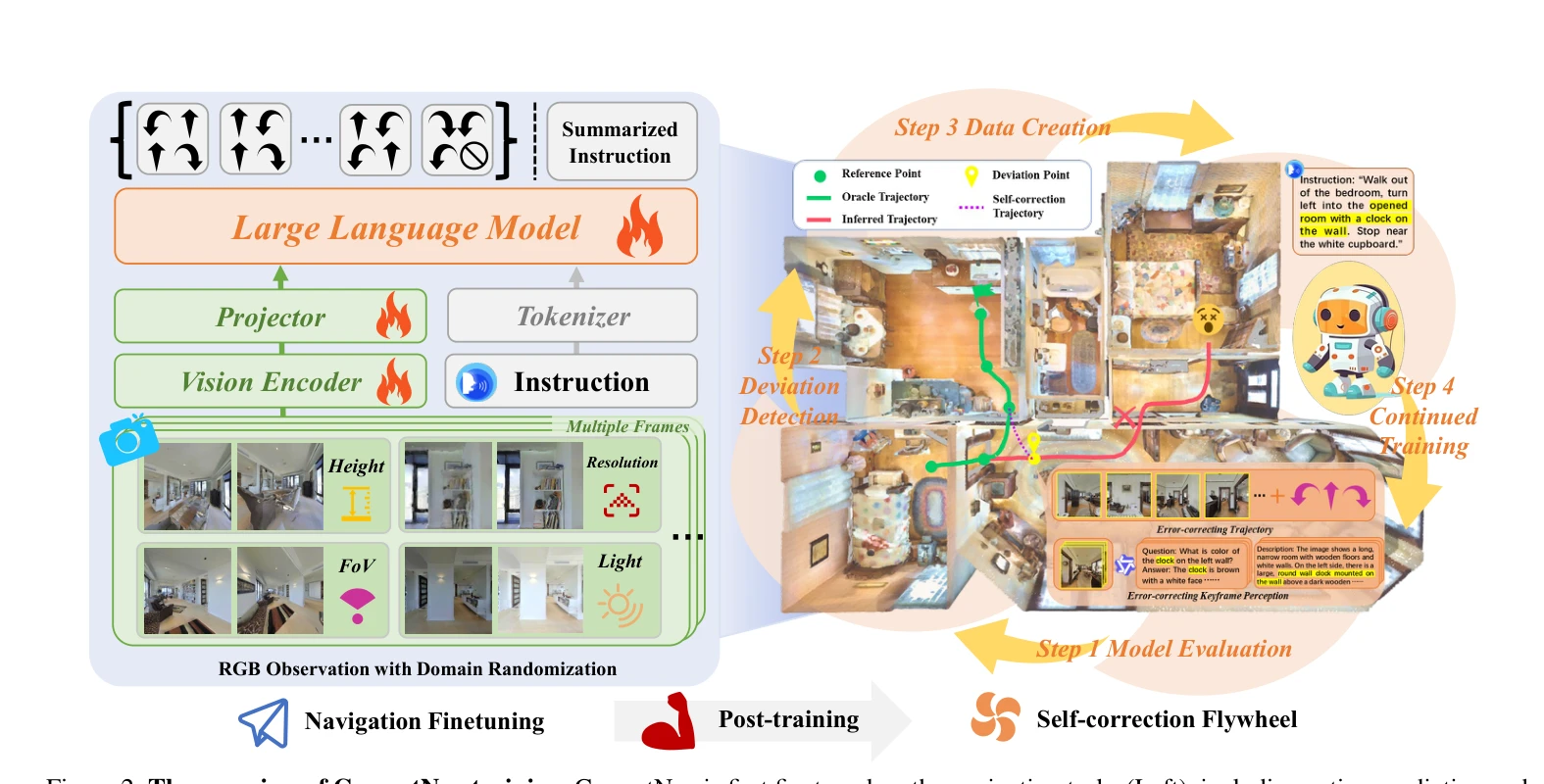
Vision-and-Language Navigation 모델의 오류 복구 능력을 강화하기 위해 Self-correction Flywheel이라는 새로운 포스트트레이닝 패러다임을 제안하여 R2R-CE와 RxR-CE 벤치마크에서 최고 성능을 달성했다.