저자: Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, Shuran Song | 날짜: 2023-03-07 | URL: https://arxiv.org/abs/2303.04137 📄 PDF
Essence
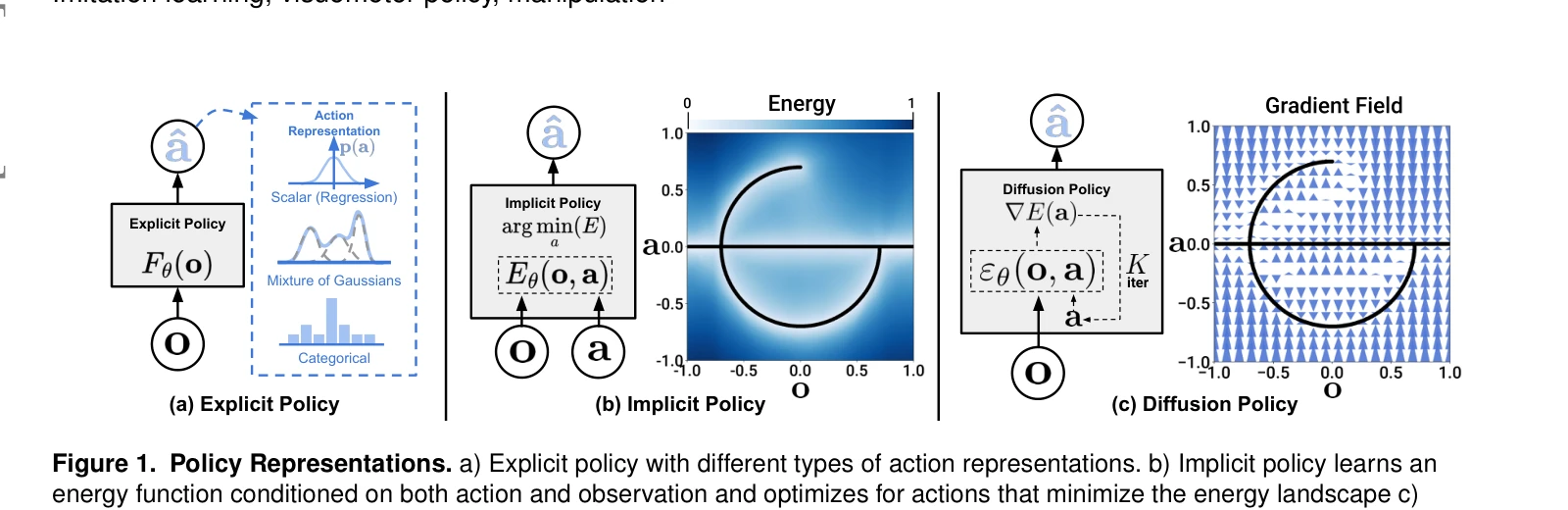
Figure 1. Policy Representations. a) Explicit policy with different types of action representations. b) Implicit policy
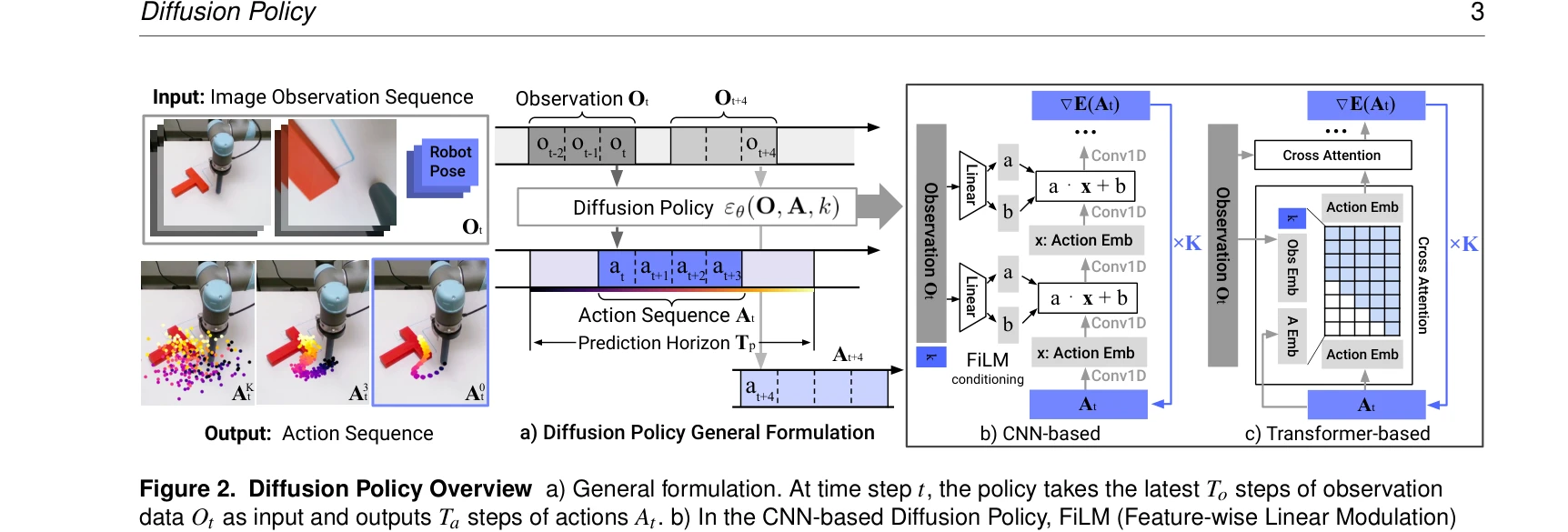
Robot 조작 작업을 위한 visuomotor policy를 conditional denoising diffusion process로 표현하는 Diffusion Policy를 제안하며, 4개 벤치마크의 15개 작업에서 평균 46.9% 성능 향상을 달성했다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: Diffusion model의 강력한 생성 능력을 robot policy learning에 창의적으로 도입하여 multimodality, scalability, training stability 문제를 동시에 해결한 획기적 연구로, 광범위한 실험과 기술적 기여를 통해 robot learning 분야에 새로운 패러다임을 제시한다.