Essence
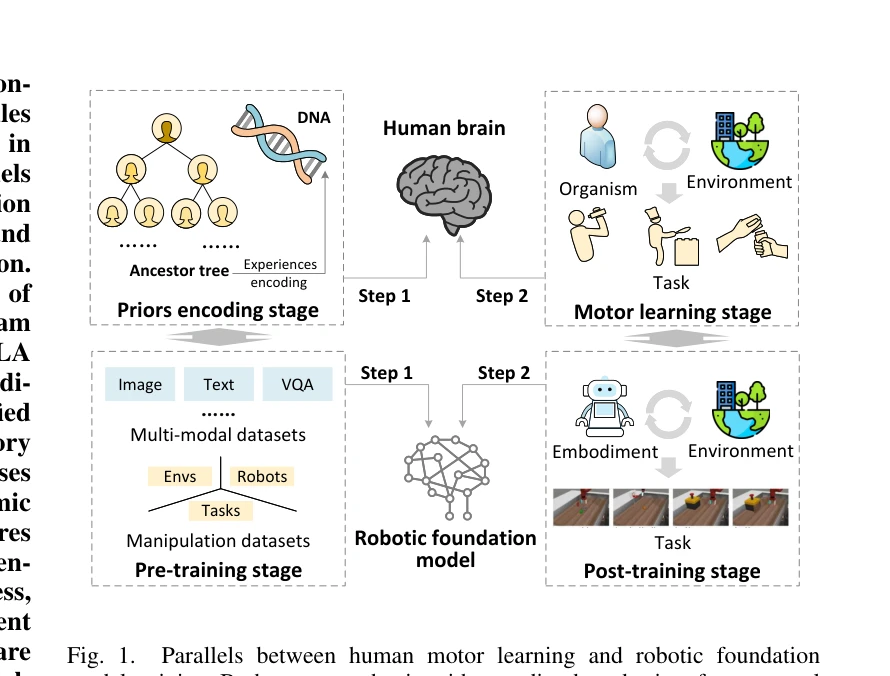
Fig. 1.
본 논문은 Vision-Language-Action (VLA) 모델의 post-training 방법을 인간의 운동 학습 이론(Newell의 제약 주도 이론)의 관점에서 종합적으로 분석하고, 환경 지각, 신체 인식, 작업 이해, 다중 요소 통합의 4가지 범주로 체계화한 설문 논문이다.
저자: Tian-Yu Xiang, Ao-Qun Jin, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Sheng-Bin Duan, Fu-Chao Xie, Wen-Kai Wang, Si-Cheng Wang, Ling-Yun Li, Tian Tu, Zeng-Guang Hou | 날짜: 2025-06-26 | URL: https://arxiv.org/abs/2506.20966 📄 PDF
Fig. 1.
본 논문은 Vision-Language-Action (VLA) 모델의 post-training 방법을 인간의 운동 학습 이론(Newell의 제약 주도 이론)의 관점에서 종합적으로 분석하고, 환경 지각, 신체 인식, 작업 이해, 다중 요소 통합의 4가지 범주로 체계화한 설문 논문이다.
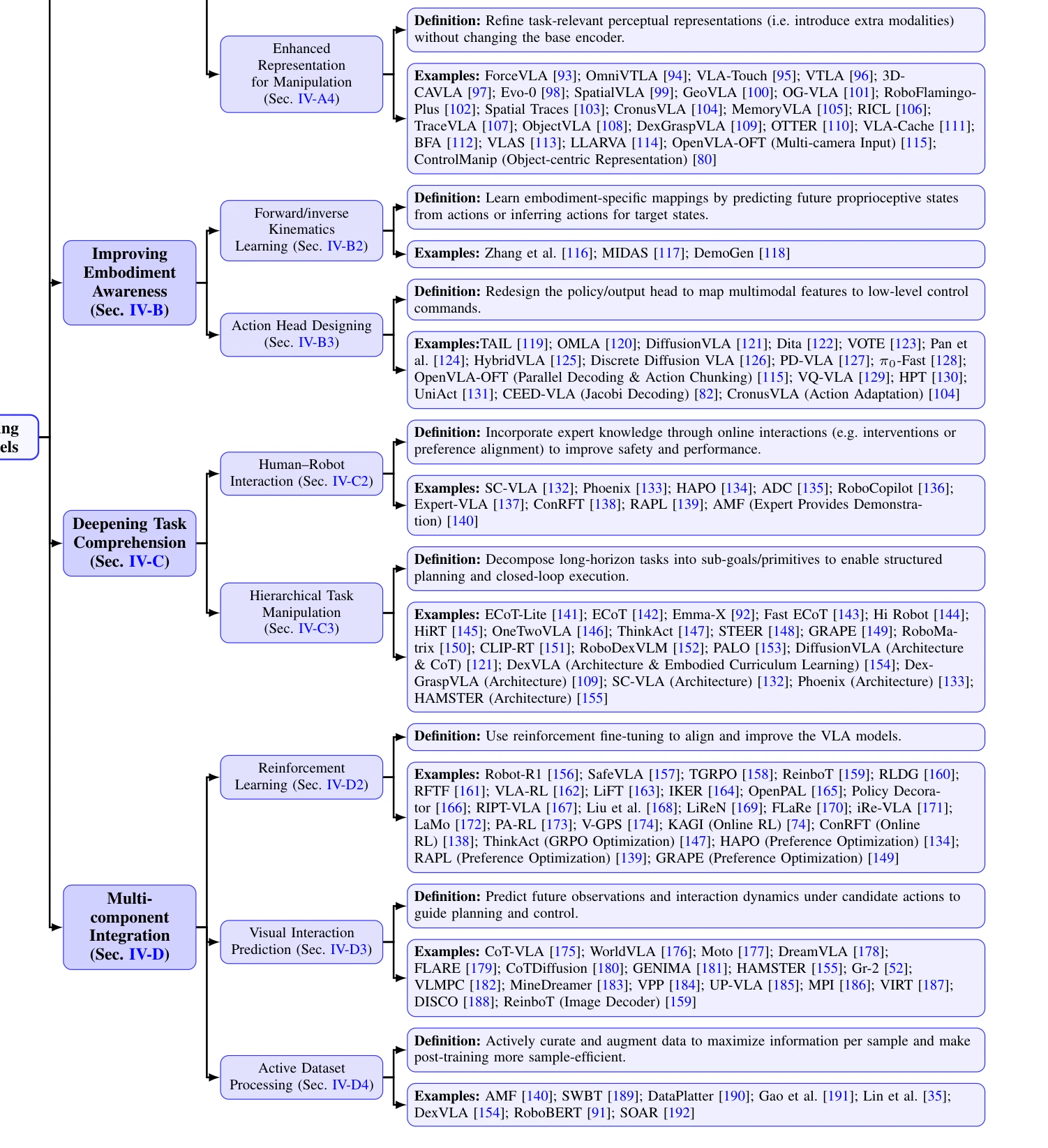
Fig. 4. Taxonomy of post-training VLA models proposed in this study.
총평: 본 논문은 VLA model post-training을 인간의 운동 학습 이론으로 통합 분석한 창의적인 설문 논문으로, NeuroAI 패러다임의 중요성을 강조하며 로봇공학 커뮤니티에 명확한 가이드라인을 제공한다. 다만 이론적 프레임워크 제시 중심이므로 각 범주의 구체적 기술 발전과 미해결 문제에 대한 심화 분석이 추가되면 더욱 실무적 가치가 높아질 것이다.