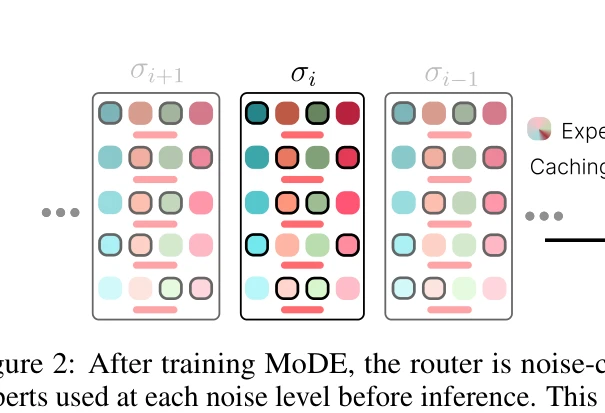
Essence
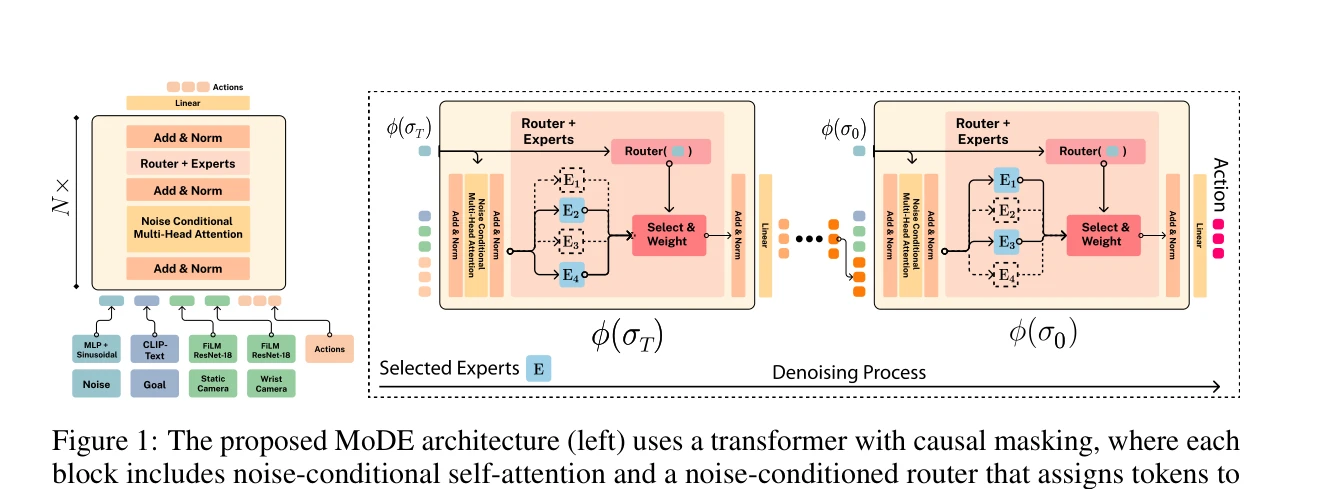
Figure 1: The proposed MoDE architecture (left) uses a transformer with causal masking, where each
MoDE는 Mixture-of-Experts 아키텍처를 Diffusion Policy에 적용하여 noise-conditioned routing과 noise-conditioned self-attention을 통해 매개변수는 40% 감소시키면서 90% 적은 FLOPs로 더 높은 성능을 달성하는 효율적인 Imitation Learning 정책이다.