Essence

Fig. 1: Our approach, CLIP-Fields, integrates multiple views of a
CLIP-Fields는 공간 좌표를 CLIP, Detic, Sentence-BERT 등 웹 사전학습 모델의 의미론적 임베딩으로 매핑하는 암묵적 신경 필드로, 직접 인간 감독 없이 로봇의 3D 의미론적 메모리로 작동한다.
저자: Nur Muhammad Mahi Shafiullah, Chris Paxton, Lerrel Pinto, Soumith Chintala, Arthur Szlam | 날짜: 2022-10-11 | URL: https://arxiv.org/abs/2210.05663 📄 PDF
Fig. 1: Our approach, CLIP-Fields, integrates multiple views of a
CLIP-Fields는 공간 좌표를 CLIP, Detic, Sentence-BERT 등 웹 사전학습 모델의 의미론적 임베딩으로 매핑하는 암묵적 신경 필드로, 직접 인간 감독 없이 로봇의 3D 의미론적 메모리로 작동한다.
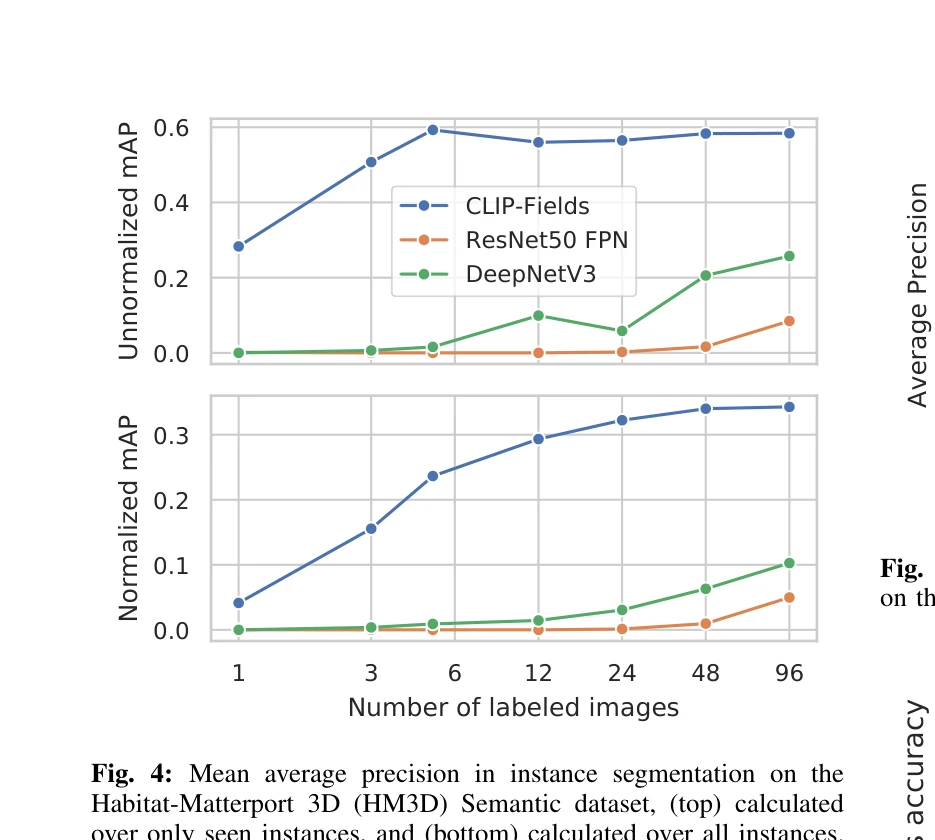
Fig. 4: Mean average precision in instance segmentation on the

Fig. 2: Dataset creation process for CLIP-Fields by processing
총평: CLIP-Fields는 웹 사전학습 모델을 활용한 약한 감독 학습으로 인간 주석을 완전히 제거하면서도 개방 어휘 기반 3D 의미론적 메모리를 구축하는 혁신적 접근법이다. 로봇 응용의 실용성과 적은 데이터로도 우수한 성능을 보여주는 점에서 매우 중요한 기여이나, 실제 로봇 환경에서의 대규모 평가 및 동적 장면 처리는 향후 과제이다.